
Since the launch of Claude Sonnet 3.5, the Sonnet class has been the de facto workhorse of production agentic deployments. It’s been the model class that proved coding agents and tool-use pipelines were viable at scale. But the last twelve months or so of capability gains concentrated mostly at the Opus tier. Sonnet stayed practical and cheap and Opus got genuinely smarter. The gap between them widened enough that teams running complex agentic workflows started routing them to Opus regardless of cost.
Sonnet 5 closes that gap in a very meaningful way. Its benchmark profile sits within a few percentage points of Opus 4.8 across agentic coding, multidisciplinary reasoning and computer use. And it runs at less than half the price per token. For teams that have been absorbing Opus 4.8 costs to hit quality targets, the calculation on where to route traffic just changed... again.
The rest of this breakdown covers what the numbers really show on the ground, where the trade-offs remain and how the GoML team is thinking about deployment decisions in light of the release.
Capability profile of Claude Sonnet 5 across the benchmark suite
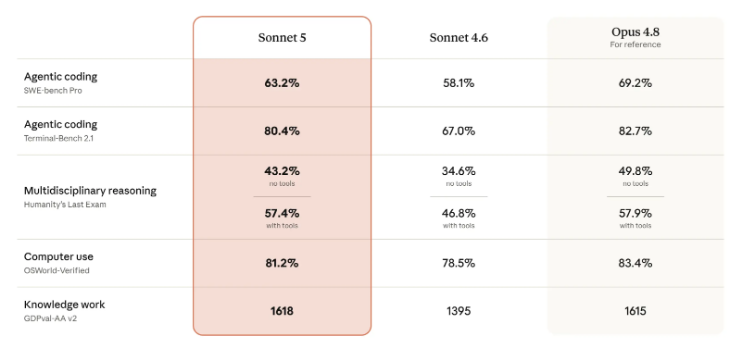
Anthropic published five benchmark categories for Sonnet 5 against Sonnet 4.6 and Opus 4.8. The jump in agentic coding is the most significant single improvement: Terminal-Bench 2.1 moved from 67.0% on Sonnet 4.6 to 80.4% on Sonnet 5, a 13-point gain. SWE-bench Pro moved from 58.1% to 63.2%.
The multidisciplinary reasoning result on Humanity's Last Exam carries a specific note: with tools enabled, Sonnet 5 scores 57.4% within 0.5 points of Opus 4.8's 57.9%. That benchmark has no clean shortcut path, so the near-parity at the with-tools level is a real signal about generalization, not benchmark-specific tuning. The knowledge work score on GDPval-AA v2 (1618 vs Opus 4.8's 1615) is the only category where Sonnet 5 outscores Opus 4.8 outright.
The effort curve of Claude Sonnet 5
The more “operationally” useful framing for production teams is the cost-performance curve at different effort levels, because that's where deployment decisions actually live. Anthropic published this for BrowseComp (agentic search) and OSWorld-Verified (computer use).
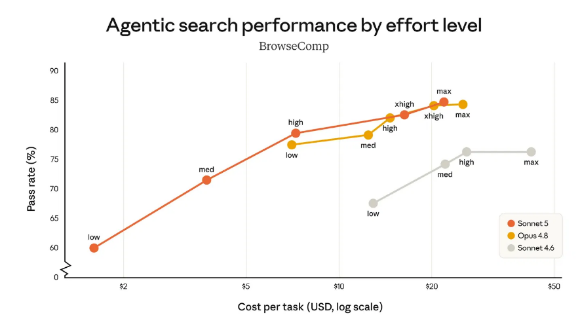
The BrowseComp curve shows Sonnet 5 starting at 60% pass rate at the lowest effort level (roughly $1 per task) and climbing to 85% at max effort (around $25 per task). Opus 4.8's curve starts higher per dollar but flattens earlier Sonnet 5 reaches Opus 4.8's performance ceiling at high effort before exceeding it slightly at max. Sonnet 4.6 doesn't appear in the same cost range until around $20 per task and peaks near 77%.
At medium effort, Sonnet 5 delivers more performance per dollar than any model in the comparison. That's the number that drives deployment decisions.
The practical read: teams running high-volume agentic workflows where medium effort is sufficient can route to Sonnet 5 and get better cost efficiency than Sonnet 4.6 at a fraction of Opus 4.8's spend. Teams running lower-volume, high-stakes tasks should compare Sonnet 5 at high-to-max effort against Opus 4.8 at medium effort the cost curves intersect in a range where the choice depends on the specific task profile.
The GoML perspective on Claude Sonnet 5
GoML delivers production AI systems into client environments. The two questions that drive every model selection decision are: does the output quality clear the bar the client's use case requires, and does the system stay auditable and compliant once it's running in the client's environment.
Sonnet 5 changes the answer to the first question for a significant portion of the workloads we currently route to Opus 4.8. The agentic coding and computer-use benchmark improvements are in the range that matters for production not marginal gains on benchmarks that don't transfer, but double-digit improvements on the tasks that agentic pipelines actually perform.
The second question is where Sonnet 5 requires a more careful read, and the safety profile section below covers that directly.
Three deployment implications stand out immediately from a GoML delivery standpoint.
- Cost structure for high-volume pipelines improves materially. A pipeline that ran 10,000 tasks per month at Opus 4.8 pricing ($5/$25 per million tokens) can move to Sonnet 5 at intro pricing ($2/$10) for the majority of that volume if the task profile matches Sonnet 5's capability range. The tokenizer change introduces a 1.0–1.35× token expansion for the same input, but intro pricing absorbs that and still delivers lower effective cost per task.
- Effort-level tuning becomes a first-class deployment parameter. Sonnet 5's wider cost-performance range means the same model can serve both high-volume medium-effort workloads and occasional max-effort deep tasks. Teams that previously maintained separate routing rules for Sonnet 4.6 and Opus 4.8 can consolidate onto Sonnet 5 plus Opus 4.8 with effort level as the switching variable.
- Partner feedback points to qualitative improvements that don't appear in benchmark tables. Early access users described Sonnet 5 completing complex tasks where earlier Sonnet models stopped short, and checking its own output without being instructed to. That self-verification behavior is directly relevant to agentic pipeline reliability a model that catches its own errors before the reviewer step reduces the cost of the verification loop.
Claude Sonnet 5 safety performance
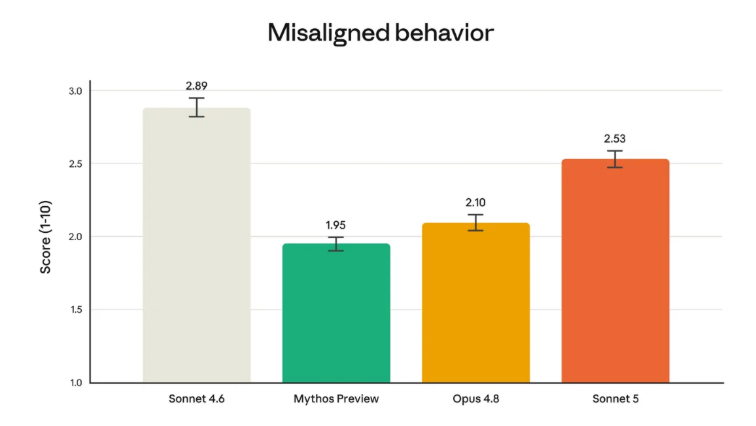
Anthropic's automated behavioral audit tests a wide range of misaligned behaviors across many situations. Sonnet 5 scores 2.53 on this audit, compared to Sonnet 4.6's 2.89. Lower is safer on this scale. Mythos Preview scores 1.95 and Opus 4.8 scores 2.10.
The honest framing: Sonnet 5 is measurably safer than its predecessor, and measurably less safe than the current Opus tier. For GoML engagements in regulated industries financial services, healthcare, legal where the safety floor is a contract condition, Opus 4.8 remains the appropriate default until the Sonnet tier closes that gap further. For product and engineering workloads where the task scope is bounded and the blast radius is scoped, Sonnet 5's safety profile is workable.
The audit also reports improvements in prompt injection resistance and lower hallucination and sycophancy rates compared to Sonnet 4.6. Both are operationally relevant for agentic systems where the model interacts with external content it doesn't control.
Claude Sonnet 5 cybersecurity protections: Documented and delibrated
Anthropic made an explicit training decision with Sonnet 5: it was not trained on cybersecurity tasks. The result is a model that can handle routine, non-harmful cyber tasks but shows substantially weaker performance than Opus 4.8 and Mythos 5 on the tasks that constitute actual security risk.
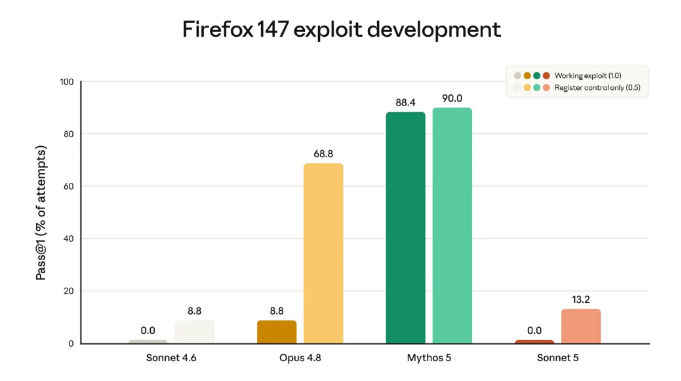
The Firefox 147 exploit development evaluation makes this concrete. Sonnet 5 produced zero working exploits across all attempts matching Sonnet 4.6 on that measure. Its partial success rate is 13.2%, slightly higher than Sonnet 4.6's 8.8%, which Anthropic attributes to general intelligence improvements rather than cyber-specific capability. Opus 4.8 produced working exploits in 8.8% of attempts. Mythos 5 reached 88.4%.
Because Sonnet 5 is somewhat stronger than its predecessor on these tasks even without deliberate training, Anthropic launched it with cyber safeguards enabled by default the same safeguards active in Opus 4.7 and 4.8. The safeguards are less restrictive than those shipped with Fable 5, calibrated to Sonnet 5's actual risk level.
The GoML read: for clients asking about Sonnet 5 in security contexts, the explicit training absence and default safeguard activation are the right answer. Clients running legitimate security tooling that requires expanded cyber capabilities should use Opus 4.8 through the Cyber Verification Program, not Sonnet 5.
GoML deployment guidance on Claude Sonnet 5
The table below reflects GoML's current read on routing decisions by workload type. These are starting points actual routing should be validated against task-representative data from the specific engagement before committing to a production configuration.
The bottom line
Sonnet 5 is the most significant Sonnet-tier release since 3.5 proved agentic coding was viable at this model class. It doesn't replace Opus 4.8 for the workloads that genuinely need its capability ceiling, and the safety gap between the two tiers remains a factor for regulated deployment environments. For the broad middle of production agentic workloads coding pipelines, computer-use agents, research synthesis, tool-use-heavy chatbots Sonnet 5 at medium-to-high effort covers the capability requirement at a cost profile that changes the economics of the engagement.
At GoML, the working assumption from today is that Sonnet 5 becomes the default routing choice for new agentic pipeline deployments, with Opus 4.8 reserved for regulated environments and tasks where the Opus safety floor is a client requirement. That assumption gets validated against specific engagement data before it becomes a configuration decision. Teams evaluating whether to route to Sonnet 5 or Opus 4.8 can model both scenarios with AI Matic before committing to a production configuration.
Run your representative workload against it. Let the cost-performance curve on your actual tasks decide the rest.
FAQs
Q1. Should teams replace Claude Opus 4.8 with Claude Sonnet 5?
Not for every workload. Claude Sonnet 5 reaches near Opus-level performance on many coding, reasoning, and computer use tasks at a much lower cost. Opus 4.8 still fits workloads with stricter safety requirements or tasks that need its highest capability level.
Q2. Which workloads are the strongest fit for Claude Sonnet 5?
Claude Sonnet 5 fits coding agents, tool use workflows, research assistants, computer use agents, and high-volume enterprise automation. Medium and high effort settings offer a strong balance between quality and cost for many production deployments.
Q3. Is Claude Sonnet 5 safe enough for regulated industries?
Claude Sonnet 5 improves on Sonnet 4.6 in behavioral safety, prompt injection resistance, and hallucination rates. Even so, organizations working with regulated financial, healthcare, or legal workloads may still prefer Opus 4.8 where stricter safety requirements apply.
Q4. What is the biggest change Claude Sonnet 5 brings for enterprise AI deployments?
The largest change is the cost versus capability balance. Many workloads that previously required Opus 4.8 now achieve similar quality with Claude Sonnet 5, allowing teams to reduce inference costs while maintaining production-grade performance.





