
Nova 2 Omni is Amazon's first all-in-one multimodal model. It can understand text, documents, images, video and audio - and generate text and images from one system, without the hassle of orchestrating and stitching together multiple models.
Andy Jassy, CEO, Amazon ended his re:Invent keynote last year with a tease of Amazon Nova Any-to-Any (A2A). It was evident even back then that Amazon was fully aware that the lack of a multimodal model capable of complex reasoning tasks will not help them compete. With Gemini and Grok making good progress in multimodality, it is evident that Amazon needed to catch up. Now, they have with Nova Omni 2.
Announced at AWS re:Invent 2025, it is designed to process text, documents, images, video and audio within a single architecture while producing both text and image outputs. The significance is multi-modal consolidation.
What makes Nova 2 Omni different
Most multimodal systems today rely on orchestration. A text model reasons. A vision model interprets images. Another model handles speech. Glue code attempts to keep state consistent across these components. As systems scale, this orchestration layer becomes the primary source of cost variance, latency drift, and failure modes.
Nova 2 Omni removes that layer. It operates as a single reasoning system that natively understands multiple input modalities and produces multimodal outputs without switching models mid workflow. This design simplifies architecture, reduces operational surface area, and improves consistency in reasoning across modalities.
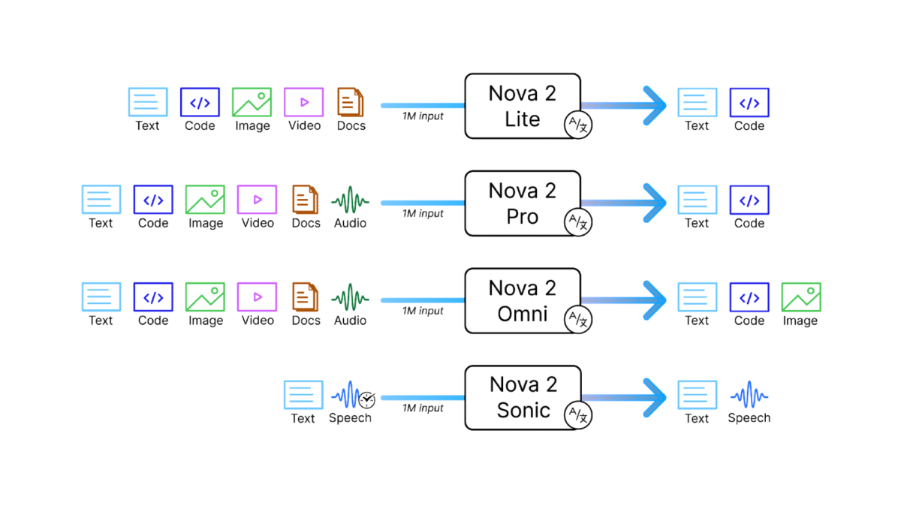
For enterprises, this directly translates into fewer moving parts and more predictable behavior at scale. Our Nova 2 guide covers the key models in the Nova 2 family.
Nova 2 Omni Capabilities
Amazon Nova 2 Omni is Amazon's first Any-to-Any Multimodal model - can process text, images, video, and speech inputs while generating both text and image. This is an industry first.
Like Google’s Gemini models, Nova 2.0 Omni is among the few AI models that can understand text, images, video, and speech natively. This is a key new differentiator for Amazon’s Nova family.
Nova 2 Omni Inputs
- Text and long-form documents
- Images and visual artifacts
- Video content
- Audio streams, including multi speaker conversations
- Speech transcription and translation
Nova 2 Omni Outputs
- High quality text
- High fidelity image generation with character consistency and text rendering support
Context
Supports up to one million tokens, enabling full document corpora, long videos, or extended conversational state to be processed in a single session
Reasoning Control
Adjustable reasoning depth to balance cost, latency, and intelligence based on workload requirements
This combination allows Nova 2 Omni to support complex enterprise workflows that previously required multiple specialized models.
Multimodal reasoning in practice
Multimodal AI is often described conceptually. Nova 2 Omni makes it operational. A single request can include a contract, a diagram, a recorded meeting, and structured metadata. The model reasons across all inputs simultaneously rather than sequentially. This preserves context and intent across modalities.
For enterprise use cases such as compliance review, clinical documentation, financial analysis, or operational diagnostics, this unified reasoning model significantly reduces ambiguity and reprocessing overhead.
How to benchmark Nova 2 Omni?
Now that the dust has settled since re:Invent, there is some data available out there to evaluate and understand the capabilities of Omni. But still, being the first of its kind, there are no true peer models to benchmark it against.
Hence, evaluations are largely conducted by comparing its individual modalities - such as image, text, and reasoning - against established industry benchmarks.
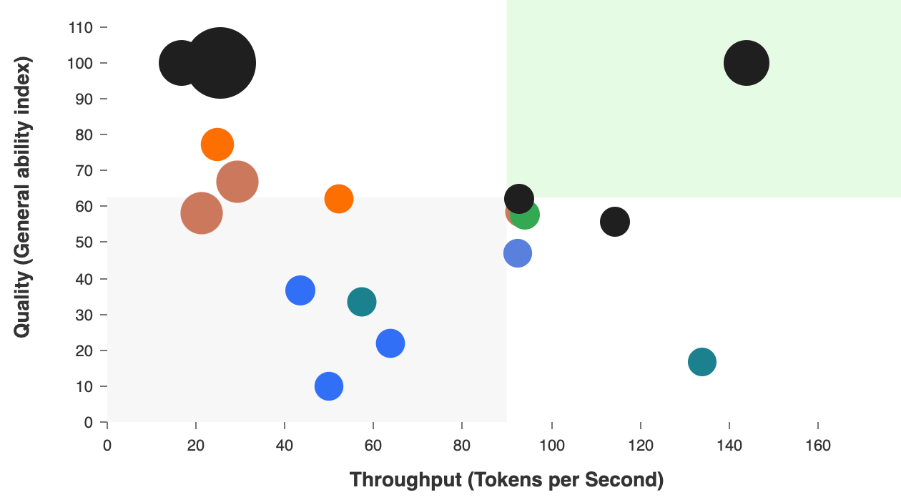
Also, since Nova 2 Omni is a unified multimodal model, it does not have direct peers... yet. Benchmarking therefore evaluates individual capability dimensions such as reasoning, instruction following, and agentic behavior against established text only models.
Text and Agentic benchmarks
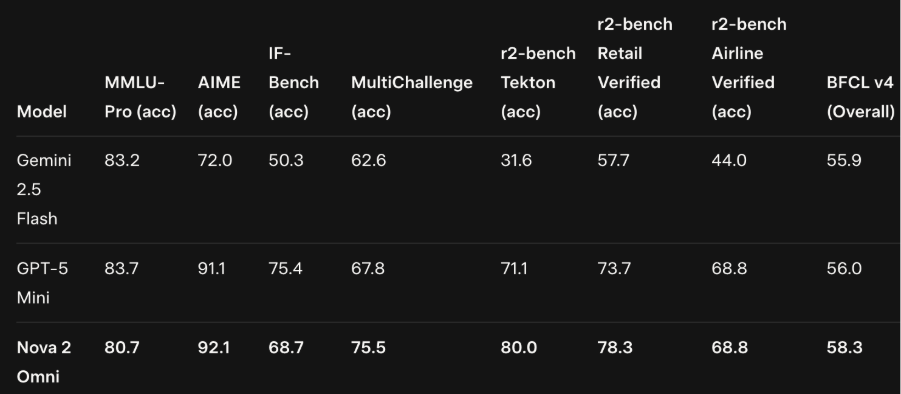
According to Amazon's Technical Report, it performs exceptionally well in multimodal perception, reasoning, and agentic tests - keeping pace with or outperforming GPT-5 Mini and Gemini 2.5 Flash. It is to be noted here that both GPT-5 Mini and Gemini 2.5 Flash can produce only text output so the evaluations with these models are primarily the text capabilities. The inputs are multimodal though.
Reasoning and knowledge benchmarks
MMLU-Pro
- Dataset of 12,000 graduate level questions across 14 domains like math, biology, and business
- Human experts score approximately 90
- Nova 2 Omni scores 80.7
This result indicates strong reasoning capability across diverse domains while operating within a multimodal architecture. The score reflects depth of reasoning rather than surface level recall. Even though other models are significantly ahead now (the table above was dated 2 Dec 2025), I believe we can cut some leeway for the multimodal output capabilities of Omni with the other models producing only text.
AIME
- Focused on complex mathematical reasoning
- Nova 2 Omni scores 92.1
This performance highlights structured problem-solving ability and logical consistency, particularly in multi-step reasoning tasks. In the AIME scores though, primarily focusing on complex math logic, Omni stands tall with a 92 - reflecting true problem-solving skill rather than simple recall.
Instruction Following and Reliability
IF-Bench
- Evaluates adherence to complex instructions
- Nova 2 Omni scores 68.7
MultiChallenge
- Measures robustness across varied instruction styles
- Nova 2 Omni scores 75.5
The IF-Bench and MultiChallenge scores, highly specialized in testing the LLM's ability to follow instructions, seem good enough for reliable and safe LLM deployment. These benchmarks matter less for leaderboard positioning and more for operational trust. Nova 2 Omni clears the thresholds required for safe and predictable deployment in enterprise workflows.
Agentic and Tool Use Benchmarks
r2-bench Verified
- Retail domain score of 78.3
- Airline domain score of 68.8
- Tekton score of 80.0
BFCL v4
- Overall score of 58.3
Likewise, the r2-bench Verified and BFCL scores, key indicators in the agentic and tool-use capabilities, reflect good potential utility in real-world collaborative environments. These benchmarks evaluate how well a model plans, selects tools, and collaborates within structured environments. Nova 2 Omni demonstrates consistent autonomy and decision making ability suitable for real world agentic systems.
For enterprise applications, these scores indicate readiness rather than experimentation. These two areas don't necessarily need the highest scores for an LLM – they are essentially thresholds for ensuring model autonomy which Omni comfortably passes. Since collaboration and instruction-following is still subjective and varies according to problem statements, these scores are to be taken with a pinch of salt.
Cost and performance characteristics
In typical AWS fashion, the costs are significantly affordable, the trade-off that most problem statements and organizations in the world willingly choose to make for a few points reduction in intelligence scores.
While some text only models score marginally higher on select benchmarks, Nova 2 Omni offers a materially stronger cost to performance ratio when evaluated across full multimodal and agentic workloads. This trade off aligns with how real systems operate. Organizations optimize for reliability, scale, and predictable spend rather than isolated benchmark peaks.
Enterprise use cases for Nova 2 Omni
Nova 2 Omni is well suited for:
- AI agents that reason across documents, visuals, and conversations
- Knowledge systems operating on large internal corpora
- Multimodal analytics for healthcare, finance, and operations
- Customer support systems requiring consistent cross channel context
- Compliance and audit workflows that span structured and unstructured data
Its unified architecture reduces system complexity while improving reasoning continuity. These align closely with the agentic and multimodal workflows we explore in our blog on AWS enterprise generative AI tools.
Potential Nova 2 Omni Limitations
Nova 2 Omni just launched. Our early beta tests have been positive. It is too early to judge though.
However, any-to-any workflows are computationally expensive. Drawbacks from Nova Premier like latency, slower response times and delays during peak usage are expected to continue. Costs could limit high-volume real-time applications. AWS usually optimizes for scale later, so early versions may feel heavy for real-time use cases.
- Any-to-any doesn’t guarantee "perfect" cross-modal alignment – audio + video reasoning might be inconsistent. These are common in Gemini, GPT-Omni, and LLaMA too.
- Amazon historically lags OpenAI, Google, and Midjourney in generative creativity - may prioritize reliability over creativity. Guardrails could limit realism or stylistic variety.
- Multimodal explainability is also an industry-wide challenge.
The Future for Nova 2 Omni
Any-to-any models are still in their early days, offering Amazon room to gain early advantage. Their multimodal reach unlocks vast potential—and marks a logical step on the path toward more general AI capabilities.
By combining multimodal understanding, long-context reasoning, and agentic execution within one architecture, Nova 2 Omni can reduce system complexity while improving reliability and predictability at scale. Its benchmark performance signals maturity across reasoning and autonomy, and its cost profile aligns with real production requirements rather than experimental usage.
As AWS continues to expand the Nova family, Omni establishes a solid foundation for AI systems that are designed to run like infrastructure. For enterprises focused on deploying AI that can be trusted, scaled, and operated with discipline, this is a meaningful step forward.
Meanwhile, we do have more information about Nova 2 and the larger AWS AI ecosystem.






