
AWS Clean Rooms have been around for 3 years, as a way for companies and partners to collaborate on and analyze data, without losing control of their datasets. At AWS re:Invent 2025, AWSannounced a major new capability for AWS Clean Rooms: privacy-enhancing synthetic dataset generation for ML model training.
This addition to AWS Clean Rooms now allows users to train machine learning models on sensitive, collaborative data without exposing individual private information.
This is yet another tool in the AWS AI ecosystem and we'll discuss exactly why.
What are AWS Clean Rooms?
AWS Clean Rooms helps companies and their partners more easily and securely analyze and collaborate on their collective datasets—all without sharing or copying one another's underlying data. This makes it useful for tasks like market analysis, consumer insights, and targeted advertising, where data collaboration is needed but data privacy is paramount.
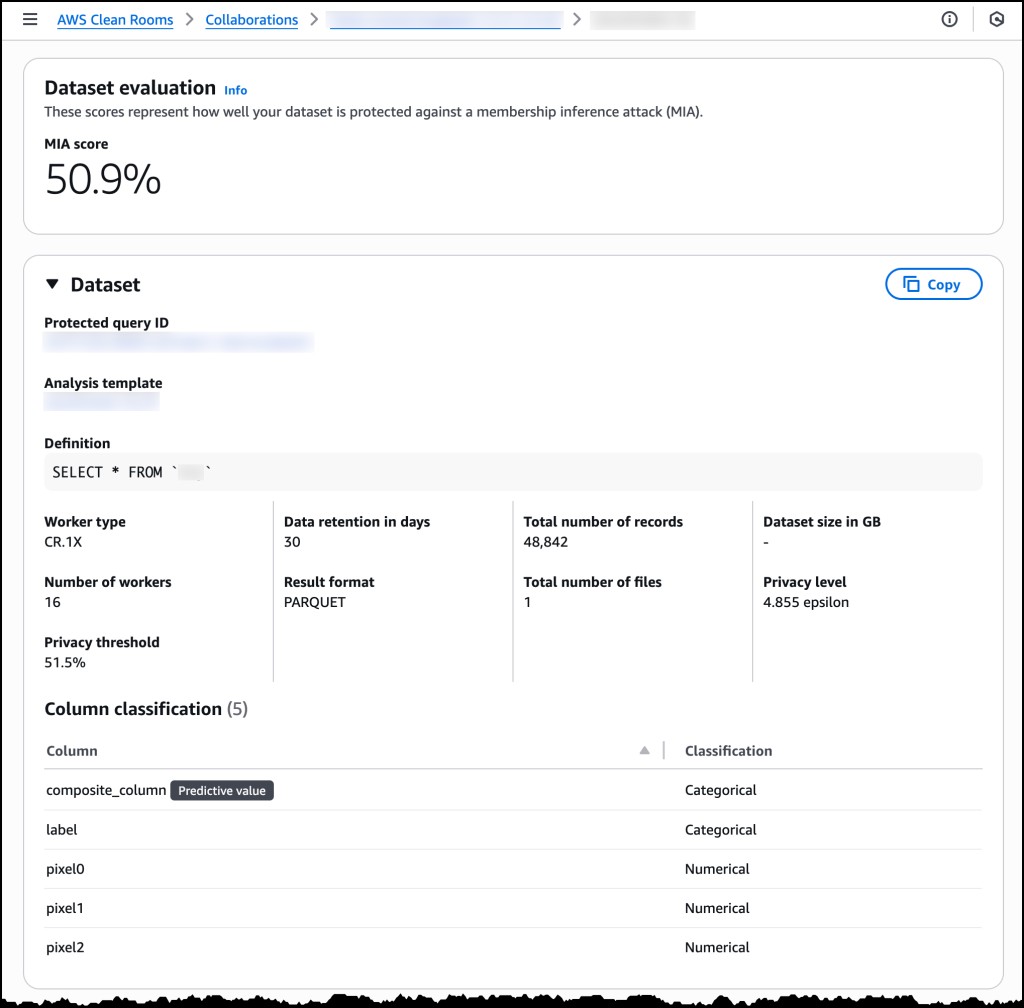
Synthetic and private ML data for AWS Clean Rooms
While building ML models, developers are routinely placed on the horns of a dilimma - data usefulness or privacy. Granular, user-level data helps train accurate models that can spot trends and personalize experiences. But using that data, especially when it comes from different parties, raises serious privacy and compliance challenges.
Companies want to know things like, “What characteristics indicate a high-probability customer conversion?”, “What attributes does indicate an user with a specific medical condition or political party? ” and so on. But training on individual-level signals often clashes with privacy rules and regulations in intractable ways.
AWS has now enabled the ability to use ML to generate synthetic training datasets that preserve the statistical characteristics of the original data without exposing any underlying records in AWS Clean Rooms ML. For companies, this removes a ton of friction involved in training and enables new model-training opportunities.
How does synthetic ML data work?
Traditional anonymization techniques such as masking still carry the risk of re-identifying individuals in a dataset. Synthetic dataset generation addresses these privacy risks by taking a different approach: a model learns the statistical patterns of the original data and then generates synthetic records by sampling features and predicting target values. Rather than duplicating or tweaking real records, the system reduces model capacity to prevent memorization of individual data points. The output maintains the same schema and statistical properties as the source, enabling downstream ML training while greatly lowering re-identification risk.
Synthetic ML data at GoML
At GoML, we work with a significant number of healthcare organizations in areas like medical imaging, diagnostics, early anomaly detection, predictive healthcare analysis, clinical workflow automation and so on. This capability is a big leap for privacy-safe machine learning in healthcare, letting teams train better models together while still keeping individual data private.
A typical use-case would be when there is a need for multiple collaborators - an academic medical center, hospitals, biopharma companies, research institutes coming together to conduct clinical research for the development of a new drug or therapy. Each collaborator will need to support the dataset and ML model training without exposing or infringing upon each other's sensitive and proprietary data.
Additionally, synthetic datasets created from our existing solutions and case studies, will boost the accuracy of GoML’s boilerplate offerings, enabling stronger results from day one and cutting down significantly on development and deployment effort.
This article is part of our comprehensive guide to AWS AI. Explore the guide to know more about AWS AI tools like Bedrock and SageMaker, AWS AI LLMs like Nova, and why AWS AI infrastructure is the best way to build gen AI based solutions that can scale in production






