
Every enterprise AI team worth their salt running multi-model workflows knows about this particular friction - you pick the best model for a task, you build the integration, then a better model ships and the whole selection rationale shifts.
You pick a second model for a different task, now you're maintaining two SDKs, two sets of credentials, two cost curves and a routing layer you wrote yourself that nobody else understands. Multiply that across six workflows in a client environment and you've built a super complex maintenance surface before you've shipped the actual product.
Good news is that Sakana AI's Fugu is a direct answer to that problem. The framing is 'one model', but what runs underneath is a dynamically assembled pool of specialized models coordinated, routed and verified automatically. From the outside it's a single OpenAI-compatible API endpoint. From the inside it's a learned multi-agent orchestration system backed by two ICLR 2026 papers.
For a team ours at GoML one that delivers production AI pipelines into client environments, this distinction definitely matters. The question worth asking about Fugu is: what does it change about how you architect a system, and where does it actually belong in a production stack?
What Fugu actually does
The standard multi-agent setup requires a human architect to define team structure upfront -
Which model handles reasoning,
Which handles code generation,
Which verifies output.
That design is baked into the system at build time and stays frozen until someone changes it manually.
Fugu inverts this. It’s a lightweight coordinator the product of learned orchestration research assembles agents dynamically per task, assigning roles as the work demands rather than as the architect anticipated.
The system identifies what the task needs and routes accordingly. You write one prompt and point it at one endpoint. The internal coordination is Fugu's problem.
The skill that compounds here is knowing what to hand off... and Fugu makes that handoff invisible at the API layer.
Two variants ship. Fugu targets everyday workloads where latency matters: code review, responsive chat, continuous integration triage. Fugu Ultra extends the agent pool depth for tasks where answer quality is the ceiling and speed is secondary paper reproduction, security assessments, Kaggle-style optimization runs, deep patent analysis. Both sit behind the same endpoint.
Fugu's research foundation: TRINITY and Conductor
Sakana grounds Fugu in two papers accepted at ICLR 2026, which is worth noting because it means the coordination mechanism has gone through external peer review rather than existing only as a proprietary claim.
TRINITY - A lightweight evolved coordinator that orchestrates multiple LLMs across several turns. It assigns each participating model to a Thinker, Worker, or Verifier role adaptively the role assignment shifts as the task progresses rather than staying fixed. Evaluated across coding, math, reasoning, and knowledge retrieval.
Conductor - Trained with reinforcement learning to discover natural-language coordination strategies. The Conductor designs the communication patterns between models and writes the focused prompts that each model receives, rather than relying on hand-written routing rules. The key finding: a learned coordinator consistently outperforms any single worker model in the pool, including the strongest one.
The practical implication of both papers is the same: the coordination layer is the product, not the models it routes. Models in the pool can be updated or swapped without rebuilding the orchestration logic. That's the architectural property that matters for production systems.

Sakana AI Fugu: One API, smarter routing, better production AI architecture
Fugu's benchmark reality check
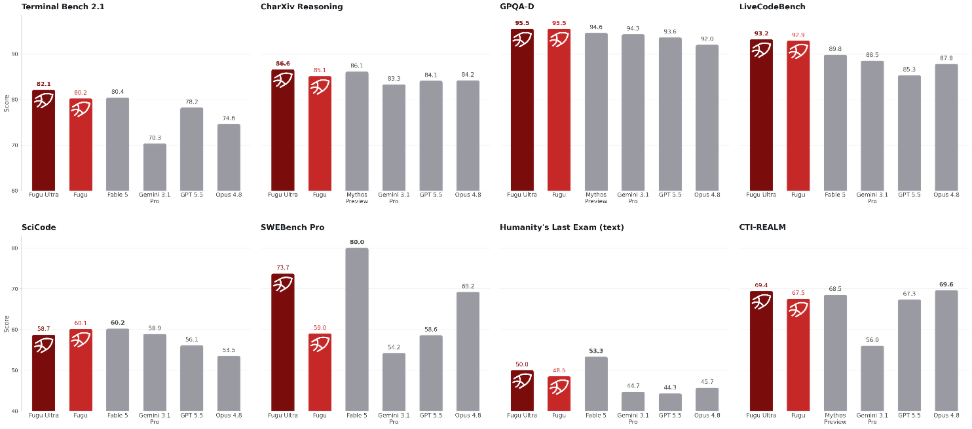
The fascinating thing is Fugu's published numbers put it shoulder-to-shoulder with Opus 4.8, Gemini 3.1 Pro, and GPT 5.5 across a range of engineering, reasoning, and scientific benchmarks. Fugu Ultra leads on several coding and agentic tasks outright. The table below uses provider-reported scores for the baselines, so read absolute numbers with appropriate skepticism benchmark conditions rarely transfer cleanly to production.
Provider-reported scores for baselines. Fugu Ultra leads SWE-Bench Pro, LiveCodeBench, LiveCodeBench Pro, and Humanity's Last Exam outright. Opus 4.8 and Mythos Preview are not in Fugu's agent pool neither is publicly accessible.
Two numbers in this table stand out from a GoML evaluation standpoint. Fugu Ultra's SWE-Bench Pro score of 73.7 is the single highest in the comparison, and it runs on mini-swe-agent scaffolding rather than a heavier harness. That combination competitive scaffold, strong result suggests the coordination mechanism is doing real work rather than the scaffolding carrying the score. The Humanity's Last Exam score of 50.0 is the other signal worth tracking: that benchmark has no clean optimization path, so strong performance there points to genuine generalization across the agent pool.
The GoML perspective on Fugu
GoML operates at the intersection of enterprise AI delivery and production engineering. The majority of clients we work with have two concerns that don't always align: getting the highest-quality output on complex tasks, and keeping the system auditable, compliant, and stable once it's in production.
Fugu addresses the first concern directly and has an interesting answer for the second. The agent pool is configurable - specific providers or models can be opted out to meet data residency, privacy, or compliance constraints. For clients in regulated industries, that's not just another nice-to-have. It's the condition under which the system can run at all.
Three properties in Fugu's design land well from a delivery standpoint.
- Single API surface reduces integration maintenance. A system that routes internally means the client-facing integration stays stable even as the underlying model pool evolves. GoML has watched too many production pipelines break on model version bumps a stable API contract above a dynamic routing layer is genuinely valuable.
- Thinker/Worker/Verifier role separation is already how we build agentic pipelines manually. Fugu makes this automatic. The Conductor's RL-trained coordination is doing what a senior AI engineer would design by hand on the first day of an engagement and doing it per task rather than as a fixed architecture.
- Persona stability across long sessions, flagged in early user feedback, is relevant for agent products that maintain context across multi-hour autonomous runs. Drift in agent behavior between turns is a real failure mode in production agentic systems not a benchmark issue, a deployment issue.
The gap worth acknowledging: Fugu is currently unavailable in the EU/EEA while GDPR compliance work is ongoing. For GoML engagements with European clients or data residency requirements outside supported regions, that's a hard blocker until the compliance pathway resolves.
Where Fugu fits in a production stack
The deployment decision for Fugu isn't whether it's good the benchmarks and early user evidence suggest it is. The decision is where in the stack its coordination layer adds value, and where existing architecture is already doing that job.
Strong fit
Complex multi-step tasks where the right model mix shifts per problem: security assessments, research synthesis across large document sets, ML experiment automation, code review at depth. Fugu Ultra's agentic ML research result running 123 experiments autonomously on a single GPU and reaching the best mean BPB across all tested systems is the clearest signal of where it operates well.
Moderate fit
Production chatbots and code review tools where Fugu's lower-latency variant handles the volume and the coordination overhead stays invisible to the user. The single-endpoint design makes this a drop-in for systems already calling an OpenAI-compatible API.
Consider carefully
Workloads with strict data residency or model-specific compliance requirements. The opt-out mechanism for specific providers handles some of this, but the pool composition at any given turn depends on Fugu's coordinator, not a human configuration file. For clients who need full auditability of which model processed which data, that needs explicit verification before deployment.

Pricing: How the model stacking works
Fugu's pricing has one unusually clean property: model fees don't stack. When multiple agents activate in a single Fugu request, you're charged at the rate of the highest-tier model involved, not the sum of all models that ran. For workloads where the coordinator pulls in several specialized models, that's a meaningful cost control compared to running those models independently.
Fugu Ultra pricing is fixed for the fugu-ultra-20260615 model version. Context threshold for extended pricing is 272K tokens.
The Fugu Ultra output rate of $30/1M tokens (rising to $45 above 272K context) sits at the premium end of the current frontier model market. For workloads where Fugu Ultra materially outperforms a cheaper model and the SWE-Bench Pro and HLE numbers suggest it does on hard tasks — the cost differential closes fast when you account for the reduction in retry loops and human review cycles. For simpler workloads, Fugu's dynamic routing defaults to cheaper underlying models, and you only pay for what actually activates.
What to watch
- EU/EEA compliance resolution. The GDPR pathway will determine whether Fugu is available to a significant portion of the enterprise market. The timeline for that work is currently unspecified.
- Agent pool transparency. Sakana publishes benchmark results but doesn't publish the current pool composition. For production deployments where model-level auditability matters, that's a question worth putting directly to their enterprise sales channel.
- TRINITY and Conductor paper results vs production behavior. Academic benchmarks and production workloads diverge. GoML's standard practice before deploying a new model layer into a client environment is running it against task-representative data from that engagement. The papers are strong signal, not a substitute for that evaluation.
- Coordinator evolution. The coordination mechanism is the product's core differentiation. How Sakana updates the coordinator model over time and whether version-specific behavior is preserved for production deployments will matter as the system matures.
The one-line read
Fugu is the most technically grounded answer to the multi-model orchestration problem that has shipped along with the commercial product so far. The research backing is peer-reviewed, the benchmark results hold across multiple task categories and most importantly, the API design removes the integration overhead that makes multi-agent systems expensive to maintain.
For GoML, the evaluation question is straightforward: does the coordination layer do something meaningful that our current stack doesn't, and does it do it in a way that survives client compliance requirements? On the first question, the evidence from TRINITY and the Conductor says yes for complex agentic tasks. On the second, the answer is conditional until the EU compliance gap closes and the agent pool composition is auditable at the provider level.
Worth a structured pilot on the next engagement where the task profile matches. Start with Fugu Ultra on a bounded research or code-review workload. Measure output quality, latency and cost per task against the current baseline. Let the numbers decide the integration path same standard as any other infrastructure decision.
Stay tuned to the GoML blog to keep up with the latest in AI and ML engineering.
FAQs
Q: What is Sakana AI Fugu?
A: Fugu is a multi-agent AI system from Sakana AI that routes tasks dynamically across a pool of specialized models, exposed through a single OpenAI-compatible API endpoint.
Q: How is Fugu different from using multiple LLMs directly?
Fugu's coordinator (trained with RL) assembles agents per task automatically and no manual routing logic or multi-SDK maintenance required.
Q: What is Fugu Ultra best used for?
Deep-research tasks, security assessments, complex code review, and ML experiment automation where output quality matters more than latency.
Q: Is Fugu available in the EU?
Not currently, GDPR compliance work is ongoing, with no confirmed timeline.
Q: How does Fugu pricing work with multiple agents?
You're charged at the rate of the highest-tier model activated, not the sum model fees don't stack.
.jpg)




