
GPT-5.5, internally called “Spud,” launched on April 23, 2026. While the AI community is still evaluating its real world capabilities, our internal testing shows clear benefits when combined with strong orchestration and tooling.
Instead of focusing only on chatbot interactions, GPT-5.5 is built for persistence-based workflows like multi-step coding, document analysis, web research, and spreadsheet creation. Its main advantage is efficiency, delivering stronger output with fewer retries, lower token consumption, and reduced API costs.
Here is what you should know about it when making an assessment about building with or adopting it.
.svg)
First impression of GPT-5.5 from a production lens
The majority of LLM updates are presented as gradual improvements in more accurate benchmarks, higher accuracy levels, and better reasoning scores. GPT-5.5, on the other hand, with its workflow-nativeness and capability to understand intent, represents a behavior change.
GPT-5.5 is a complete retrain of the base model, not an incremental release on top of GPT-5.4, equipped with a native multimodal architecture, optimized for long-context reasoning and agentic workflows 1M+ token context window with 40% improved token efficiency
1. Agentic coding: Closing the gap?
With strong endorsements from teams at tools like Cursor, Lovable, and Windsurf, GPT-5.5 appears well-suited for agentic coding workflows. However, while the gains are noticeable, it is less clear whether they represent a true shift in capability compared to models like Anthropic's Claude, which have historically been strong in coding and long-horizon tasks.
What is Terminal-Bench?
Terminal-Bench is a free and publicly available benchmarking suite for testing the performance of agents when performing multiple tasks such as system administration, debugging, and compiling software in CLI environments. This version is an improvement on Terminal-Bench 1.0 developed by Stanford, and unlike its predecessor, Terminal-Bench 2.0 is extremely difficult and is very well-tested; in some cases, an hour or even days may be required.
Terminal-Bench 2.0 covers 89 tasks across:
- Software engineering
- Git and version control
- Machine learning
- Data science
- Networking

How does GPT-5.5 fare on Terminal-Bench?
According to OpenAI’s official release, GPT-5.5 achieves a state-of-the-art accuracy of 82.7%, a significant jump from OpenAI’s previous best of 62.9% which itself was already ahead of Anthropic’s Claude Opus 4.6 at 58.0%.
On paper, this looks like a clear step change.
Interestingly, open-source CLI-based AI coding harnesses like ForgeCode report pushing GPT-5.4 to ~81.8% on similar tasks. This raises an important question: how much of this performance gain comes from the model itself, and how much from the surrounding system - the harness, orchestration, and execution logic?
We strongly believe that the quality of an agent is more about orchestration than the inherent LLM itself. This is why we often see well-engineered pipelines built on mid-tier models outperform poorly orchestrated systems using frontier models - the marginal gains from raw capability start to flatten eventually.
This also highlights a broader, often overlooked reality: for a large share of real-world use cases, baseline model performance is already sufficient. Beyond a certain point, incremental gains in benchmark scores have diminishing impact unless they translate into better reliability, lower cost, or improved system behavior.
To probe this further, it’s useful to look beyond the aggregate Terminal-Bench 2.0 scores. Platforms like Artificial Analysis, a data-driven evaluation hub, have introduced a more constrained variant: Terminal-Bench Hard, a subset designed to isolate the most challenging tasks.
We believe this distinction gives us a better picture of where the models stand since a large portion of “easy” and “medium” tasks aren’t necessarily about reasoning but more about language comprehension and tool usage. Including these in aggregate accuracy can inflate perceived “reasoning” performance. Focusing on harder subsets provides a clearer signal of how models behave under genuine complexity.
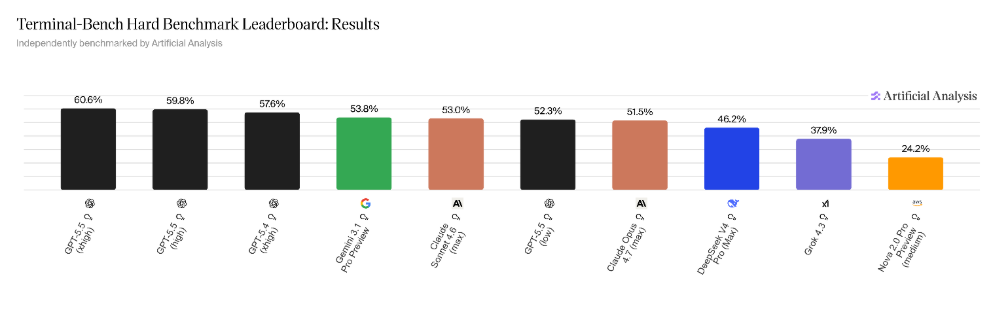
On Terminal-Bench Hard, OpenAI GPT-5.5 still leads - but the gap narrows considerably. Models from Google DeepMind (Gemini) and Anthropic (Claude) are not far behind. At this level, differences increasingly feel like a function of:
- fine-tuning
- orchestration strategies
- agent design rather than raw model capability alone.
Models like Nova 2.0 lag more noticeably in this setting, although that likely reflects release cadence and optimization priorities rather than a fundamental ceiling something that we anticipate as one of the next major updates from the AWS Bedrock ecosystem.
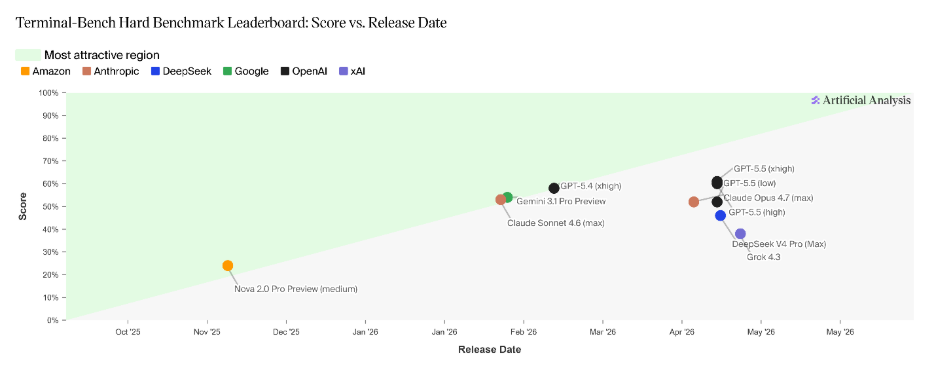
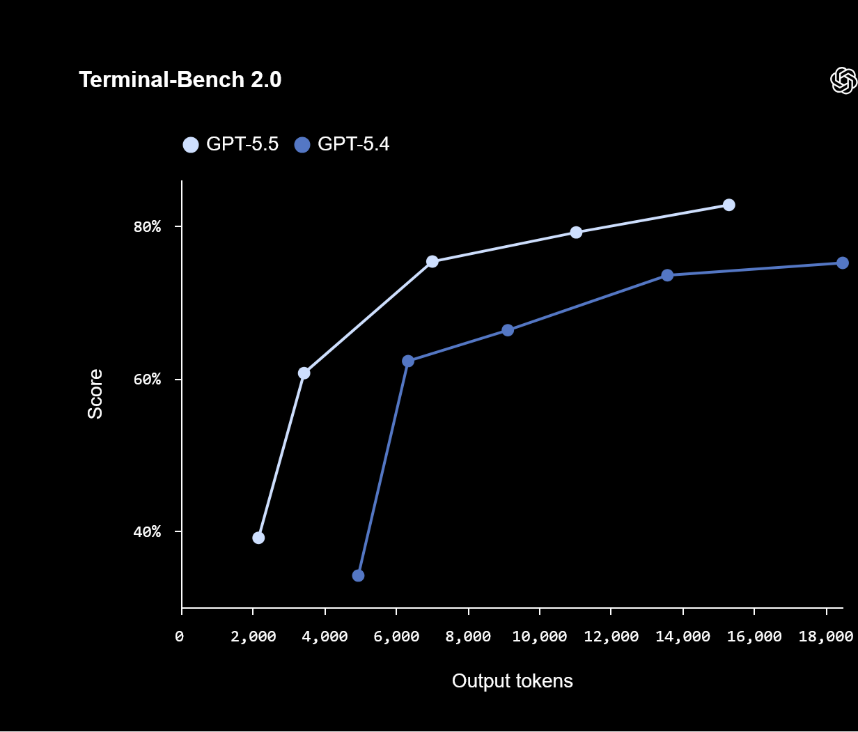
Where GPT-5.5 does stand out more clearly is in efficiency.
When viewed through the lens of score vs token usage, the gap becomes significant. OpenAI GPT-5.5 achieves comparable or better performance with fewer tokens, indicating more efficient inference. At scale, this translates directly into lower latency and reduced cost per task - arguably more impactful than marginal gains in accuracy.
This efficiency is not incidental. GPT-5.5 was co-designed, trained, and served on NVIDIA’s GB200 and GB300 NVL72 systems, with optimizations around load balancing and partitioning. These system-level design choices show up clearly in real-world performance characteristics.
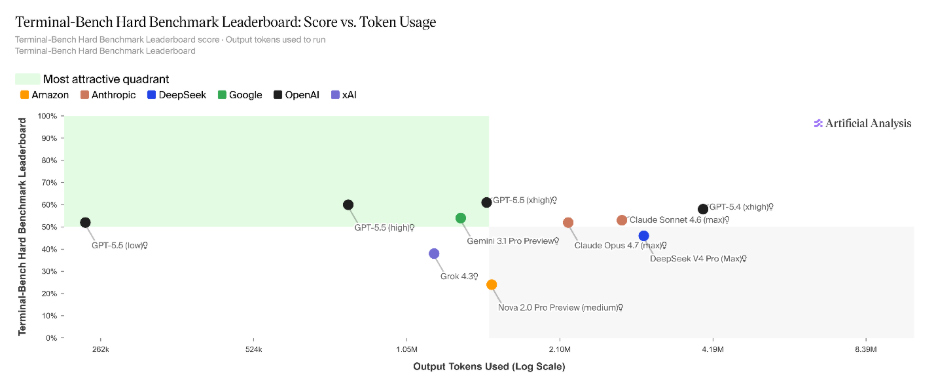

2. Knowledge work: Where benchmarks break down
Early signals from OpenAI point toward capabilities that resemble desktop-level agents systems that can interpret on-screen context, navigate interfaces, and move across tools with a higher degree of intent awareness.
This aligns with a broader industry direction, where prototypes like OpenClaw and subsequent releases such as Amazon’s Quick suggest a move toward interface-native AI systems models that don’t just generate outputs, but operate within software environments.
What stands out in early feedback is GPT-5.5’s ability to handle loosely defined, real-world tasks:
- operational analysis
- spreadsheet modeling
- structuring ambiguous business inputs into actionable plans
These are qualitatively different from coding benchmarks. The challenge is not just reasoning, but:
- interpreting incomplete or messy inputs
- maintaining context across multiple steps
- making implicit decisions under uncertainty
This makes knowledge work significantly harder to evaluate. Unlike agentic coding where benchmarks like Terminal-Bench provide clear success criteria - knowledge work introduces a high degree of subjectivity.
What is GDPval?
GDPval is an evaluation benchmark introduced by OpenAI to measure how well AI systems perform on real-world, economically meaningful tasks. Unlike traditional benchmarks that focus on narrow problem-solving or academic reasoning, GDPval is designed to reflect work that professionals actually do.
The benchmark spans:
- 44 occupations
- 9 major industries, including legal, engineering, customer support, and healthcare
Many of these tasks are intentionally scoped to represent multi-hour efforts for human professionals - often requiring 7+ hours of work - making them closer to real-world deliverables than isolated prompts.
It focuses on generating professional work products such as legal briefs, engineering blueprints, or marketing plans and is evaluated by human experts through blinded pair-wise comparisons to assess practical utility rather than academic knowledge.
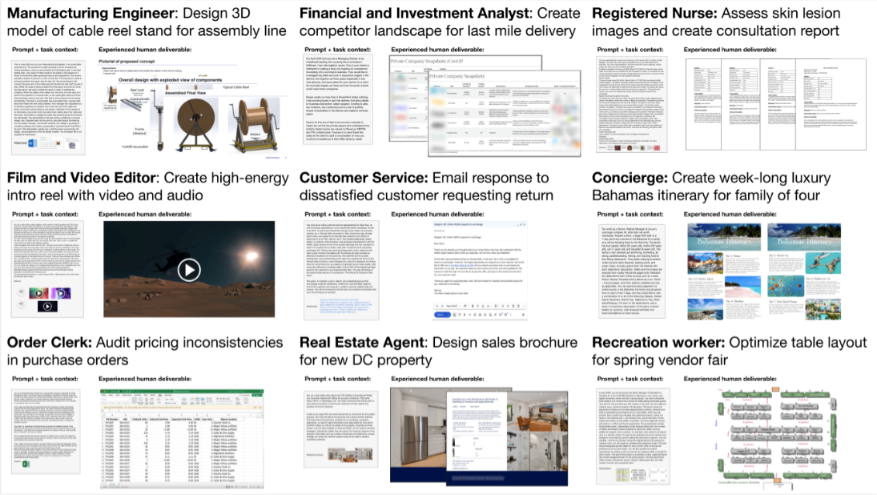
To make this more concrete, here are a few representative examples of the types of tasks included in GDPval
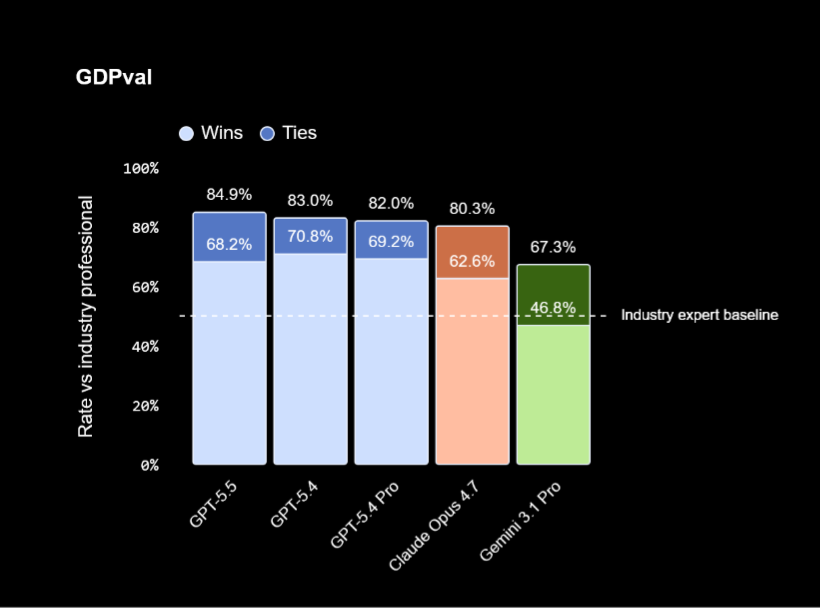
GPT-5.5 on GDPval
For GDPval, OpenAI's report indicates that the best score for GPT-5.5 stands at 84.9%, followed by GPT-5.4. However, there are two major drawbacks of GDPval:
- One-shot evaluation: It primarily evaluates single-pass outputs, whereas real-world knowledge work is iterative, multi-turn, and feedback-driven.
- High subjectivity: Scoring relies on human pairwise comparisons, making reproducibility and consistency more challenging.
However, even with the more advanced GDPval-AA model that uses an artificial harness known as Stirrup, OpenAI GPT-5.5 continues to rank above all other systems. Nevertheless, it should be noted that the difference of about 20 Elo points means that the probability of winning is less than 53%, meaning that all of these models belong to one class. With the introduction of an artificial harness, there is much less differentiation between frontier systems.
How does GPT-5.5 fare?
On GDPval, OpenAI reports GPT-5.5 achieving a top score of 84.9%, with GPT-5.4 following closely behind with a higher Ties% (cases where human evaluators judge the model’s output to be on par with expert-generated work). GPT-5.5 pushes slightly ahead in outright preference wins.
Given that GDPval is introduced and curated by OpenAI, it’s reasonable to assume that model iterations are aligned with the benchmark’s evaluation philosophy - particularly its emphasis on end-to-end work products and human-perceived utility.
However, GDPval has two main limitations that I believe are significant:
- One-shot evaluation – it primarily evaluates single-pass outputs, whereas real-world knowledge work is inherently iterative, multi-turn, and feedback-driven.
- High subjectivity - since scoring relies on human pairwise comparisons, results are influenced by evaluator judgment, domain interpretation and contextual expectations. This makes reproducibility and consistency more challenging.
To get a more rounded picture, it’s useful to look at Artificial Analysis’s GDPval-AA, which extends GDPval into a more realistic setting by introducing an agentic loop. Tasks are executed through a standardized harness (Stirrup), and performance is measured using Elo ratings derived from blinded pairwise comparisons.
This setup matters because it reduces variance introduced by custom orchestration and isolates how models perform within a consistent execution framework.

Here too, OpenAI GPT-5.5 comes out on top.
However, the gap is narrower than it first appears. When evaluated under a shared harness like Stirrup, models from OpenAI and Anthropic tend to cluster closely in Elo ratings. A ~20-point Elo difference borrowing intuition from chess - places models within the same skill tier, translating to only a ~53–54% win probability.
This reinforces an earlier point that I made in the previous section - Once you standardize the harness, differences between frontier models compress, and system design begins to matter as much as raw capability.
Where GPT-5.5 continues to differentiate is in efficiency. Across evaluations, it consistently achieves strong performance with lower token usage, indicating more efficient inference. At scale, this translates into tangible benefits in latency and cost per task.
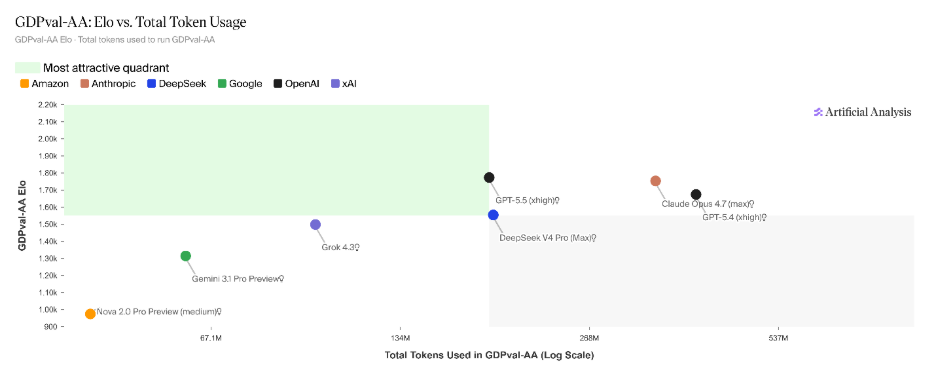
However, knowledge work introduces a different constraint: who the end user is.
Unlike agentic coding where users are typically technical and performance-driven many knowledge work use cases target non-technical. Users, business stakeholders and operational teams. For these users, cost sensitivity often outweighs marginal performance gains.
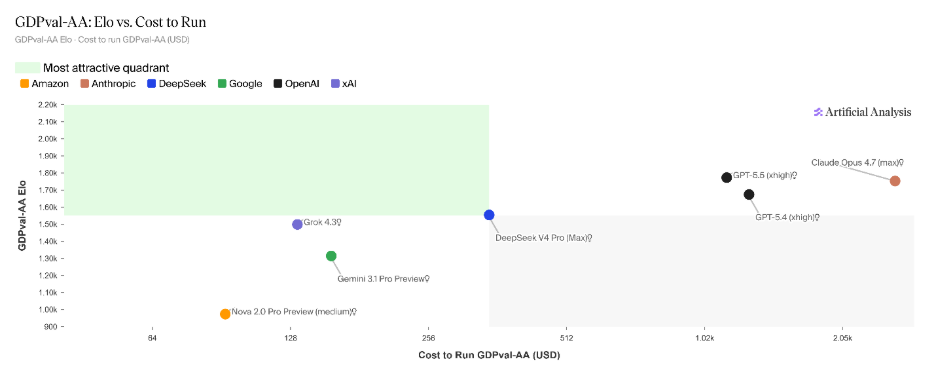
This changes the trade-off considerations - an Elo improvement that translates to a small increase in output preference may not justify higher per-task cost. Low-cost profiles with “good enough” models might be preferred in many real-world cases with GPT-5.5 is likely shining in high-stakes workflows and deep research tasks.
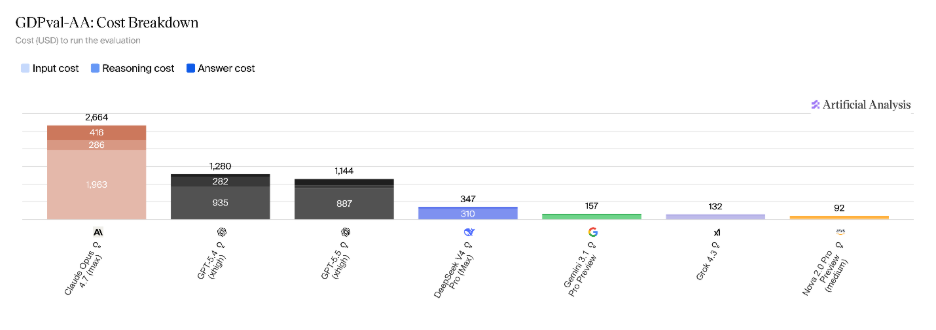
Overall, GPT-5.5 shows clear improvements in efficiency particularly in token usage and inference characteristics, while advances in reasoning appear more nuanced when evaluated in system-level contexts. The trajectory is directionally sound, but the gap over competing models is narrower than headline metrics suggest.
Based on the current signals, GPT-5.5 likely edges ahead for me, but remains broadly comparable to models like Anthropic’s Claude Opus series, with differences increasingly shaped by orchestration rather than raw model performance.
Coding agents that complete tasks without stopping
GPT-5.5 is shipped with the integrated Codex. It comprehends your prompt in the initial phase of the chat, asks fewer follow-ups, and carries out the job based on that. At Artificial Analysis on the Coding Index, the performance figures of GPT-5.5 are impressive considering it does not cost twice its price as compared to other competing frontier coding models.
Key benchmark scores to know
- GDPval (44-job agent benchmark): 84.9%
- OSWorld-Verified (autonomous computer environment tasks): 78.7%
- Tau2-bench Telecom (customer service workflows, no prompt-tuning): 98.0%
All high scores but benchmarks are most trustworthy when real-world results match. Keep this in mind when evaluating for practical applications.
Business and data science tasks
The tests performed with GPT-5.5 Pro and GPT-5.4 Pro revealed definite progress in the fields of business analysis, legal analysis, and data science. The answers were more structured and comprehensive because of the ability to perform the task from start to finish without interruptions.
Safety and security considerations
OpenAI conducted a comprehensive testing process for GPT-5.5, which includes all safety and readiness processes. These include an entire red team that tests its cybersecurity and biology aspects more thoroughly compared to some earlier releases.
Moreover, the Trusted Access for Cyber initiative provides organizations responsible for safeguarding vital infrastructure with unrestricted access to the cybersecurity capabilities of GPT-5.5.
Mixed real-world results
As per Tom's Guide, OpenAI GPT-5.5 was directly compared to Claude Opus 4.7 on seven metrics, and GPT-5.5 lost on all seven counts. Apparently, GPT-5.5 was extremely fast but produced highly confident yet wrong results without indicating uncertainty. Such an outcome raises many red flags in scenarios where precision is critical, such as the legal and healthcare industries.
Excellent benchmarks but poor results in practice. Remember this discrepancy when assessing its suitability for practical use cases.
To ensure reliable outputs from the model, apply GPT-5.5 within structured workflows instead of using random prompts. GoML's AI Matic enables you to convert GPT-5.5 into reliable workflows for code writing, documentation, and automation purposes.

Production failure modes
The advancements in reasoning and multi-step execution with the GPT-5.5 have brought a whole new category of features but also a whole new category of failure. In practice, this often results in failures that are more sophisticated and harder to spot:
- Long-horizon drift: Small errors compound, mistakes propagate, and the model deviates from the original goal.
- Over-orchestration: Overuse of tools, inefficient chaining, hidden failure points, and unnecessary complexity.
- Context overload: Longer context windows (1M+ tokens) do not necessarily mean better decisions; prioritization and signal-vs-noise separation is often imperfect.
- Silent hallucinations: Subtle insertions and plausible-but-unsupported details that are difficult to catch.
Points to an underlying tradeoff gains in complex reasoning do not always translate to uniform reliability across all task types.
Another commonly cited limitation is token pricing. While GPT-5.5 is more efficient in token usage, its cost profile remains a constraint for many use cases - particularly those involving high-frequency or low-margin tasks.
In domains like healthcare, these failure modes are not just technical concerns - they are operational risks leading to missed or misinterpreted clinical signals, incorrect but plausible outputs and critical information being overlooked. These are not failures that every system can afford.
Mitigating these risks requires more than better models it requires robust evaluation, validation layers, and system-level safeguards.
Healthcare-specific risks
For instance, in medicine, such failure modes are not only technical problems but operational issues such as overlooking signs, producing inaccurate results that seem reasonable, and missing key information.
Such failure modes are too costly for all systems to endure. Addressing these problems requires more than building better models; it requires thorough testing and verification.
Overall assessment
While OpenAI GPT-5.5 does demonstrate a marked improvement in efficiency, especially when considering the use of tokens and inference behavior, the progression made in reasoning has proven somewhat less straightforward, especially in terms of system-level assessments. It's definitely headed in the right direction, but the lead over its competitors is not as large as some might hope.
At this point, GPT-5.5 will likely provide an edge over its competitors for agent-based tasks and deep research, though it should still be even-steven with other models such as the Claude Opus line from Anthropic. It's now becoming more about how well you can orchestrate your processes than which model you use.
What we are testing next?
This is the first part of series.
In the coming weeks, we’ll evaluate GPT-5.5 alongside models like DeepSeek V4 across real healthcare workflows against GoML’s internal evaluation suite. Our focus will be on:
- Task Completion Rates - percentage of workflows completed end-to-end
- Failure Mode Analysis - hallucination, omission, tool misuse, drift
- Cost vs Outcome - cost per successful task (not per token)
- Prompt Sensitivity - variance under controlled input changes
- Production Readiness - reliability, latency, and consistency
The goal is to evaluate models in the way they operate in production, not in isolated benchmark settings.
More detailed findings, comparisons, and workflow-level observations will follow as testing continues.
About GPT-5.5 Instant
OpenAI has introduced GPT-5.5 Instant as the new default model powering ChatGPT across all user tiers. Replacing GPT-5.3 Instant, it delivers faster, more reliable, and more context-aware interactions while improving reasoning, factual accuracy, and response quality.
The model can also shift dynamically into deeper reasoning workflows when more complex analysis is required. More importantly, GPT-5.5 Instant reflects OpenAI’s broader shift toward coordinated assistant systems where memory, retrieval, routing, multimodal understanding, and safety mechanisms work together to shape the overall user experience.
The numbers that moved
- 52.5% reduction in hallucinations across medical, legal, and financial evaluations
- 37.3% fewer inaccurate responses in conversations users had previously flagged for factual errors
- 81.2 on the AIME 2025 math benchmark, up from 65.4 on its predecessor
- Roughly 30% fewer words per response while maintaining equivalent informational density
The hallucination reduction is the headline here. For the same high-stakes domains where GPT-5.5 exposed production reliability problems, healthcare, legal, and finance, GPT-5.5 Instant directly targets factual stability at the default interaction layer.
That matters because real-world trust is usually determined less by peak capability and more by consistency. A model that is slightly less flashy but substantially more dependable is often more valuable than one that sounds impressive while being wrong.
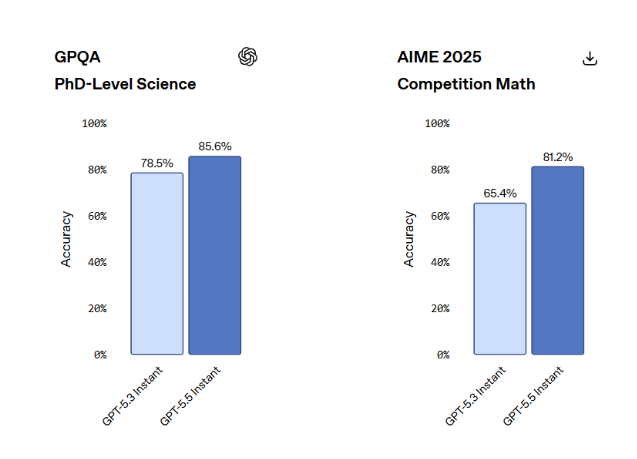

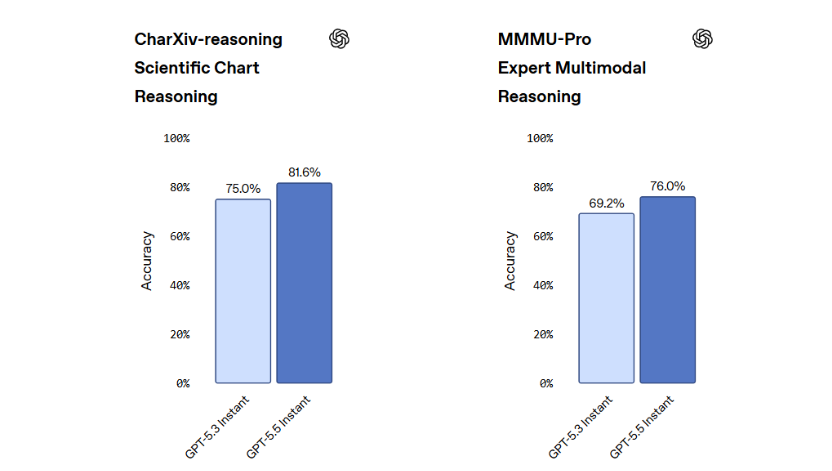
Cleaner responses and better communication
Older instant tier models frequently generated verbose responses, riddled with too much formatting, superfluous follow-ups, and redundant structure. GPT-5.5 Instant seems to reduce that tendency considerably.
Replies are more concise, coherent, and disciplined. The assistant seems more tuned to when explaining, organizing, and stopping. That may seem trivial, but in practical product use, response discipline is very important to perceived intelligence.
This is part of a broader product design change. OpenAI seems to be trying to make ChatGPT seem less like a text generator and more like an assistant that can communicate effectively.
Stronger reasoning without sacrificing speed
Historically, “Instant” models were fast but shallow. GPT-5.5 Instant begins to break that trade-off.
OpenAI appears to have improved reasoning depth while preserving low-latency interaction design. The model performs substantially better on mathematical and multimodal benchmarks while still functioning as a speed-first assistant for daily usage.
From a systems perspective, this is a difficult optimization problem. The model must feel immediate, remain affordable to deploy at massive scale, and still maintain reasoning quality high enough to serve as the default assistant experience for millions of users.
GPT-5.5 Instant looks like OpenAI’s current answer to that balance.
Better image understanding and multimodal fusion
Real workflows are increasingly multimodal. Users ask questions about screenshots, dashboards, diagrams, handwritten notes, whiteboards, UI mockups, charts, and scanned documents.
GPT-5.5 Instant handles these workflows significantly better than previous instant-tier models.
The important distinction is that this appears to go beyond basic image captioning. The assistant increasingly integrates visual information directly into reasoning and conversational generation. This multimodal fusion expands ChatGPT’s role from text helper to broader digital problem-solving interface.
A stronger multimodal assistant can now:
- analyze dashboards
- interpret flowcharts
- understand UI layouts
- reason through visual data
- assist with scanned documentation
- work across text and image context simultaneously
That significantly broadens the practical usefulness of the default assistant experience.

Smarter search judgment and retrieval logic
One of the most underrated upgrades is better search judgment.
GPT-5.5 Instant appears better at deciding:
- when internal knowledge is enough
- when live web search is needed
- when retrieval would only add latency
- when outdated information creates factual risk
One poor search decision can derail an otherwise strong answer. The assistant should not search for everything, but it also cannot rely on stale information when freshness matters.
This reflects a broader shift in AI systems. Modern assistants increasingly depend on retrieval orchestration, pulling the right context from memory, uploaded files, conversation history, connected services, and live web sources before generation even begins.
Memory-aware personalization
Premium users can now ground responses using:
- prior conversations
- uploaded files
- archived materials
- connected services and external context
GPT-5.5 Instant also introduces stronger memory-aware context selection. The assistant appears better at retrieving relevant historical information while avoiding unrelated or stale context.
A new source attribution mechanism shows which stored references influenced a response, improving transparency around personalization behavior. Users maintain direct control over stored memories and can remove or modify references when needed.
This reflects a broader shift away from stateless chat systems toward persistent assistant architectures capable of maintaining continuity across longer workflows and repeated interactions.
Technically, this means assistant intelligence increasingly depends on:
- memory ranking
- contextual relevance
- retrieval precision
- continuity management
- personalization transparency
The model itself is only part of the experience.
GPT- 5.5 Instant’s architecture point
GPT-5.5 Instant is not just a standalone language model. It behaves more like a coordinated assistant system.
Before generating a response, the system may:
- assess prompt complexity
- retrieve memory or uploaded context
- decide whether web search is needed
- route simple tasks through fast inference paths
- escalate harder prompts to deeper reasoning systems
- apply safety and formatting controls
That entire process can happen before a single response appears on screen.
This is why modern AI quality increasingly depends on orchestration, not just model intelligence. Retrieval quality, routing accuracy, memory relevance, search behavior, latency optimization, and safety systems now shape the final user experience as much as the model itself.

Safety as part of the architecture
GPT-5.5 Instant is not deployed raw. It operates inside a broader framework involving:
- classifiers
- policy systems
- mitigations
- filtering layers
- deployment-specific controls
- privacy-aware safeguards
This is increasingly important because production-quality AI requires balancing capability with reliability, privacy sensitivity, and operational safety.
Modern assistant systems are no longer evaluated solely on raw intelligence. They are evaluated on how safely and consistently that intelligence behaves under real-world usage conditions.
This represents another important industry shift. Safety is no longer treated as a separate moderation layer attached after deployment. It is increasingly embedded directly into the assistant architecture itself.
What this means for developers and builders
For developers and product teams, GPT-5.5 Instant highlights a major shift in AI: application quality now depends as much on orchestration as raw model capability.
Prompting still matters, but so do retrieval systems, memory handling, search logic, grounding, routing, and multimodal processing.
As assistants become more system-driven, failures can come from retrieval errors, weak routing, stale search results, memory selection, or safety layers, not just the model itself.
The challenge is no longer simply generating text. It is assembling the right context at the right time.
The honest picture
Taken together, GPT-5.5 and GPT-5.5 Instant show where OpenAI is heading and improving the entire assistant stack, from advanced reasoning systems to the everyday default experience.
The biggest differentiator is no longer benchmark performance alone. It is operational reliability:
- fewer hallucinations
- better retrieval
- stronger contextual awareness
- cleaner responses
- safer deployment
- more dependable multimodal reasoning
Challenges still remain. Dynamic routing can make outputs harder to reproduce consistently, while deeper personalization raises questions around transparency and user control. As these systems become more orchestration-driven, debugging also becomes more complex because failures may come from retrieval, memory, search, safety layers, or the model itself.
Still, the direction is becoming clear. The AI race is shifting from building the smartest standalone model to building the most dependable assistant system.
GPT-5.5 and GPT-5.5 Instant reflect OpenAI’s broader shift toward more reliable, context-aware, and multimodal AI systems. Beyond stronger reasoning and lower hallucination rates, the focus is increasingly on orchestration, retrieval, personalization, and real-world usability.
Platforms like GoML’s AI Matic further extend these capabilities by helping enterprises build and scale AI-powered workflows using models like GPT-5.5 Instant based on the context and use case. If you’re looking for a solution in the space, reach out to our experts today.
References
OpenAI GPT-5.5 Announcement: https://openai.com/index/introducing-gpt-5-5/
Artificial Analysis — Intelligence Benchmarking Methodology: https://artificialanalysis.ai/methodology/intelligence-benchmarking
Terminal-Bench: https://www.tbench.ai/
ForgeCode vs Codex CLI Comparison: https://terminaltrove.com/compare/ai-coding-agents/codex-cli-vs-forgecode/
GDPval Research Paper: https://arxiv.org/html/2510.04374v1






