
Agent Loops are one of the most specific advances in Agentic AI so far. Unlike traditional prompt-response systems, they create continuous feedback cycles where agents plan actions, execute tasks, evaluate outcomes, and adjust their approach until they reach a defined goal.
This model now allows agents to handle difficult work with far less human involvement. In software and infrastructure workflows, Agent Loops can validate code and configuration changes against real environments before they reach a pull request. The system assigns work, runs tests, linting, and type checks, reviews the results, and determines the next action based on clear signals.
This article examines how Agent Loops work, how they differ from conventional AI workflows, and how teams are using them to verify cloud-native code and infrastructure changes. It also covers common failure patterns, design considerations and safety controls for production use.
Agent loops: How AI replaces one-shot prompting in cloud-native DevOps
Every engineer who has tried to automate a failing CI fix with an LLM knows the problem one prompt isn't enough. Agent loops are not entirely a ‘new’ concept. Feedback-driven systems, control loops also autonomous workflows have existed in software engineering for decades. What has changed now is the convergence of technologies that make AI-driven loops practical, reliable plus economically valuable at production scale. Tools like AI Matic help engineering teams implement these loop-based workflows without rebuilding infrastructure from scratch.
Better models
Modern large language models have evolved from text generators into systems that can participate in operational workflows.
• Reason across longer contexts
• Follow multi-step instructions
• Use external tools and APIs
• Generate and execute code
• Adapt behavior based on feedback
This shift allows models to participate in workflows that require multiple decisions and corrections.
Mature cloud infrastructure
Cloud-native platforms provide the structured feedback that agent loops require.
Organizations now operate environments built on Kubernetes, CI/CD pipelines, observability platforms, policy engines, infrastructure-as-code, and automated testing frameworks. These systems continuously generate signals such as logs, metrics, traces, deployment events, and test results.
Agent loops use these signals as objective feedback, enabling decisions based on real system behavior instead of assumptions.
Demand for outcome automation
Organizations increasingly want AI systems that complete work rather than generate recommendations.
Examples include:
• Investigating failed builds
• Diagnosing production incidents
• Implementing code fixes
• Running verification tests
• Creating pull requests
As systems grow, manually managing these workflows becomes harder.
Why teams are using agent loops?
From prompts to loops
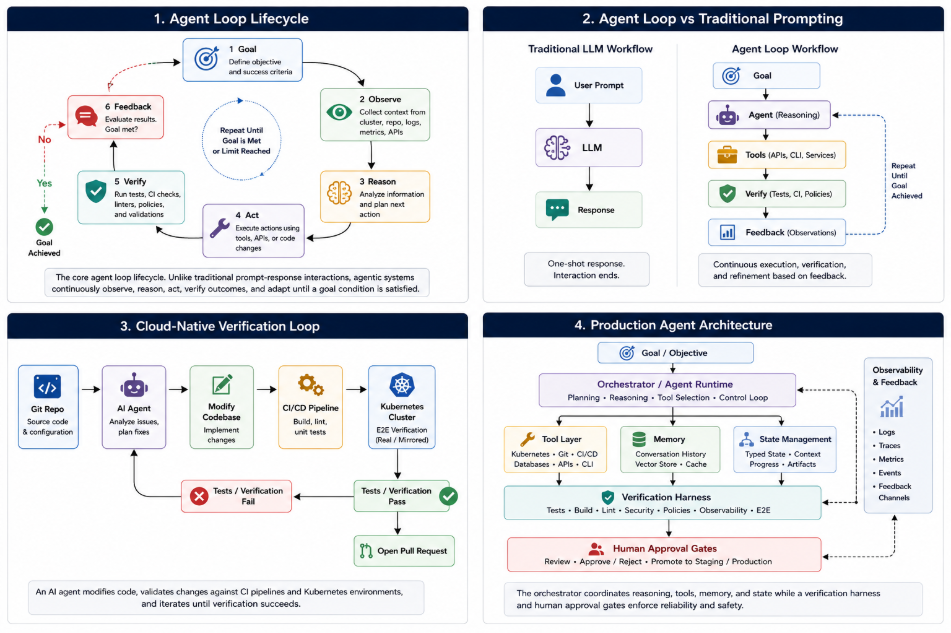
Traditional LLM usage is “one-shot”: a developer writes a prompt, the model emits an answer, and the interaction ends. This works for small tasks but falls short for real-world DevOps workflows that require multi-step investigation, retries, and verification against live systems.
Agent loops move from single prompts to continuous cycles. A typical loop:
- Receives a goal or discovers work to do.
- Observes the current state (cluster, repo, logs, metrics).
- Plans or decides the next action.
- Calls tools or APIs to execute that action.
- Observes results (test outcomes, errors, metrics changes).
- Updates state or memory.
- Decides whether to continue, branch, escalate, or stop.
This “perceive → reason → act → observe → learn” cycle continues until the loop hits a goal condition, a hard limit (steps/time/tokens), or a failure. In engineering terms, an agent loop is a control loop wrapped around an LLM and a set of tools.
Definitions: Agent, Loop, and Harness
An AI agent is a language model embedded in a loop with tools, context, and state; the model produces actions or answers, tools execute, observations are added to context, and the cycle repeats. The loop is the orchestrator that decides when to call the model again, when to stop, and how to route observations back.
Around this loop sits a “harness” the environment, tests, observability, and safety checks that constrain and evaluate the agent’s actions. In cloud-native verification, the harness often includes Kubernetes clusters (real or mirrored), CI pipelines, end-to-end tests, type checkers, linters, and logs, all wired so that failures flow back into the loop as feedback rather than to a human reviewer.
Taxonomy of agent loops
Large-scale analyses of agentic systems show that “agent loop” is not a single pattern but a family of designs. One classification group loop into three major groups and seven types:
.png)
Real systems often use hybrids: for example, a staged-gate loop that contains inner ReAct loops for each stage and constrained experiments for evaluation.
The core components of an agent loop
Although implementations vary across frameworks and use cases, most agent loops are built around five foundational components that work together to create a continuous feedback cycle. Understanding these components helps explain why agentic systems behave differently from traditional one-shot LLM workflows.
Goal definition
Every agent loop begins with a clearly defined objective. The goal provides direction, establishes success criteria, and determines when the loop should terminate.
In cloud-native environments, goals are often expressed as measurable outcomes rather than open-ended requests. Examples include fixing a failing CI pipeline, reducing infrastructure costs, resolving a Kubernetes deployment issue, or passing a specific suite of end-to-end tests. Without a well-defined goal, the agent has no reliable way to determine whether it is making progress or has successfully completed its task.
The quality of the goal definition frequently determines the effectiveness of the entire loop.
Reasoning
Reasoning is the decision-making layer of the loop. During this phase, the agent evaluates available context, analyzes observations, considers possible actions, and selects the most appropriate next step.
Modern agent frameworks increasingly employ structured reasoning approaches that decompose tough objectives into smaller, verifiable tasks. Rather than attempting to solve an entire problem in a single pass, the agent incrementally builds a plan, adapts it based on new information, and continuously reassesses priorities as conditions change.
This ability to reason between actions is what enables agents to handle ambiguity, branching workflows, and unexpected outcomes.
Action
Reasoning alone produces no value unless it results in execution. The action phase is where an agent interacts with external systems through tools, APIs, and automation frameworks.
Depending on the environment, actions may include querying databases, executing code, modifying infrastructure, interacting with Kubernetes resources, triggering CI pipelines, retrieving logs, generating pull requests, or invoking specialized services.
Actions transform decisions into observable outcomes, allowing the loop to move from planning to execution.
Observation
Every action generates new information. The observation phase captures that information and feeds it back into the loop.
Observations may include test results, deployment statuses, log outputs, performance metrics, error messages, API responses, or changes in system state. These signals provide the agent with an updated understanding of reality and form the basis for subsequent decisions.
In cloud-native verification workflows, observation is particularly important because it grounds the agent’s behavior in objective signals from real systems rather than assumptions or generated text.
Feedback
Feedback closes the loop.
The agent compares observed outcomes against its original goal, expectations, and success criteria. If the results indicate incomplete progress, failure, or a newly discovered issue, the agent updates its state and begins another iteration.
This feedback mechanism enables adaptation, error correction, and continuous improvement throughout execution. Without feedback, an agent would behave like a traditional one-shot system, producing actions without learning from their consequences.
In practice, verification mechanisms such as unit tests, integration tests, typecheckers, policy engines, and end-to-end test suites often serve as the primary feedback channels, providing objective evidence that guides the agent toward a successful outcome.
Agent loops in cloud-native verification
Cloud-native verification means testing and validating behavior in the same kind of Kubernetes or microservices environment where the code will run, rather than in local mocks. Agent loops bring verification into the loop itself instead of leaving it as a separate human-operated phase.
One emerging pattern uses an AI coding agent that modifies services, runs E2E tests against a real or mirrored Kubernetes cluster via tools like mirrord or kagent, observes failures, and iterates until tests pass before opening a pull request. Because tests run against reality rather than simplified mocks, cross-service breakages (for example, payment failures caused by a discount change in a different microservice) surface immediately to the agent, not a human reviewer.
Why loops are replacing prompts
Several forces push teams beyond one-shot prompts toward loops. First, non-trivial tasks like CI failure triage, dependency upgrades, or incident investigation require multiple steps with branching decisions, which static prompts cannot handle reliably. Second, humans acting as the “prompt loop” become a bottleneck; they must read diffs, run tests, and feed errors back to the model manually.
In a loop, the system itself finds work (e.g., failing CI runs, outdated dependencies), uses the agent to propose fixes, runs typechecks, tests, builds, and browser checks, then feeds failures back to the agent automatically. This backpressure forces the agent to fix issues before a human sees them, reserving human attention for intent and product-level decisions.
Verification inside the loop
A key design principle is to put verification inside the loop, not after it. Instead of the agent emitting a patch and a human running tests, the harness runs typechecks, linters, unit tests, end-to-end tests, build steps, and even browser checks, then pushes the structured failure signals directly back into the loop.
For example, an auto-coding loop might:
- Generate a patch to fix a bug.
- Run unit tests and typechecks in CI.
- If tests fail, capture stack traces and failing assertions.
- Feed these artifacts back into the agent as observations.
- Iterate until tests are green or a step/time budget is exhausted.
This “tight feedback loop” is especially powerful in cloud-native contexts where E2E tests can run against a real cluster via mirroring or sandboxed namespaces.
Example: Kubernetes agents with human-in-the-loop
Kagent and similar frameworks show how to embed AI agents directly in Kubernetes with explicit verification and safety patterns. Agents can read cluster state freely using tools like k8s_get_pod_logs and k8s_describe_resource, then propose changes through tools like k8s_apply_manifest or deletion commands.
Human-in-the-loop (HITL) is implemented as configuration on the agent’s tool list: destructive tools are marked with requireApproval, causing the agent to pause and ask for human approval before execution. The runtime automatically blocks the call, surfaces an Approve/Reject UI, and resumes the loop based on human feedback, while read-only tools run immediately.
Example: Autoresearch and constrained experiments
Research-oriented loops like Andrej Karpathy’s Autoresearch demonstrate constrained experimentation loops. An agent repeatedly edits a training script, runs fixed-time experiments (for example, five-minute training runs), and only commits changes that improve a chosen validation metric on a feature branch.
The loop terminates when the agent completes its task, runs out of context, or reaches a step/time limit, at which point a new agent can be spawned. This pattern generalizes to cloud-native optimization, such as tuning autoscaling parameters or caching strategies with constraints on time, cost, and cluster impact.
Engineering failure modes in agent loops
Real-world agent loops fail in predictable ways when left unconstrained. Common failure modes include infinite loops, hallucinated tool calls, and state corruption.
Infinite loops occur when the agent repeatedly calls the same tool with slightly varied parameters, interpreting every result as incomplete, without a hard step limit enforced by the orchestrator. Hallucinated calls emerge when tool schemas are too broad or underspecified, giving the model too many degrees of freedom to invent invalid or unsafe calls. State corruption happens when observations are stored as unstructured text without typed, conflict-aware state objects, leading to inconsistent beliefs about the world.
Design patterns to stabilize loops
To make loops robust, practitioners recommend explicit architectural constraints on termination, tool schemas, and state. Core patterns include:
- Hard step budgets: The orchestrator tracks step counts and terminates loops that exceed a maximum, rather than delegating termination to the model.
- Typed state objects: Instead of appending free-form text, loops maintain structured state (for example, JSON objects, typed graphs) that can be validated and diffed.
- Narrow, typed tool schemas: APIs declare strict argument types and allowed operations, preventing hallucinated or over-broad calls.
- Stop tokens or final-answer modes: Models are instructed to emit explicit markers when they believe the task is done, making termination detection deterministic.
- Duplicate-call detection: Orchestrators detect repeated identical tool calls and halt to avoid convergence to nowhere.
These patterns combine to produce loops that terminate quickly on easy tasks, fail gracefully on hard ones, and avoid unsafe behavior when tools or infrastructure misbehave.

When agent loops are worth It
Not every team needs agent loops. Analysis of practitioner reports suggests that loops pay off most when tasks are frequent, verifiable, and automatable end-to-end. A useful checklist before automating a loop includes:
- The task recurs at least weekly.
- The output can be rejected by a test suite, typechecker, build, or linter.
- The agent can run the code or system it modifies.
- The loop has a hard stop (step, token, or time budget).
- A human reviews changes before merge, deploy, or critical configuration updates.
Good first loops include CI failure triage, dependency bump PR drafts, lint-and-fix passes, flaky-test reproduction, and issue-to-PR flows in repos with strong tests. Poor candidates include security-critical code, architectural rewrites, payments/auth subsystems, and vague product decisions where “done” is inherently subjective.
Safety, governance, and access control
Production agent loops must be wrapped in safety and governance controls. In Kubernetes, patterns include scoped service accounts, fine-grained RBAC, and database branching to ensure agents cannot corrupt shared staging or production data.
Frameworks like kagent declare tool access and human approval requirements in YAML, enabling security teams to audit which tools agents can call and which require human gating. HTTP header filtering and traffic scoping prevent agents from eavesdropping on each other’s workloads, while non-destructive read tools are separated from write/delete tools to allow non-intrusive operation as a default.
Observability and feedback channels
Observability is as important for agent loops as it is for microservices. Engineers need to see which tools were called, in what order, with what arguments, and what the resulting observations and model tokens were. Logs, traces, and metrics must capture loop-level behavior step counts, failure rates, success metrics, and time-to-resolution.
Harness-native engineering emphasizes explicit feedback channels: tests, monitors, and review queues that produce structured feedback into the loop, not just human comments. This makes loops debuggable and improvable over time rather than opaque sequences of prompts.
Human roles in a looped world
Agent loops do not eliminate humans; they shift their role. The loop automates “typing work” (running commands, editing files, running tests), while humans focus on defining goals, designing verification harnesses, and making judgment calls on ambiguous outputs.
Some teams adopt wave-based delivery patterns where agents work in waves of analysis, architecture, implementation, and review, with humans approving transitions between waves. Others add explicit “orch” roles that gate agent actions until a human approves an analysis or design document. Across practices, verification and high-level judgment remain human responsibilities even when loops handle execution.
Practical design recommendations for engineers
Engineers building agent loops for cloud-native verification can follow several pragmatic guidelines drawn from current practice:
- Start with a single, manually executed workflow (for example, “fix a failing CI test”) and make it reliable with an agent before adding scheduling.
- Turn that workflow into a skill: a reusable loop that can be triggered by events (failed CI runs, new issues).
- Only then schedule or cron it; do not start with a fully autonomous scheduler.
- Put verification in the loop: tests, typechecks, builds, and E2E runs must be automated and machine-readable.
- Use hard limits and human gates for anything that touches production, security, or money.
This staged approach avoids premature autonomy and keeps complexity manageable while still reaping the benefits of tighter feedback loops.

Conclusion
Agent loops mark a major change in how AI systems are designed and deployed. The industry is moving beyond prompt engineering toward systems that can continuously reason, act, verify outcomes, and adapt based on real-world feedback. What makes agent loops powerful is not the language model itself, but the structured cycle of execution and verification that surrounds it.
In cloud-native environments, this shift is particularly significant. Modern software systems are too complex for one-shot interactions to reliably manage. Distributed services, Kubernetes clusters, CI/CD pipelines, infrastructure dependencies, and production observability all generate dynamic conditions that require iterative investigation and validation. Agent loops provide a framework for handling this complexity by grounding decisions in objective signals such as test results, deployment states, logs, metrics, and policy checks.
However, successful agentic systems are not built by simply connecting an LLM to a collection of tools. The most important engineering work happens around the loop: designing robust verification harnesses, enforcing strict tool boundaries, maintaining structured state, implementing observability, and introducing safety controls that prevent unintended actions. As organizations scale autonomous workflows, these supporting systems become just as critical as the underlying model.
The next phase of autonomous AI will likely be defined less by larger context windows or benchmark scores and more by the quality of the loops that surround models. The agents that deliver real value will be those capable of operating within well-designed feedback systems, learning from failures, validating their own work, and reliably progressing toward measurable goals.
For engineering teams, the opportunity is clear. Start with workflows that are repetitive, measurable, and verifiable. Build tight feedback loops around tests, infrastructure, and observability. Introduce autonomy gradually, with strong safeguards and human oversight. Organizations that master loop engineering today will be best positioned to deploy the next generation of AI systems, systems that do not merely generate answers but continuously work toward outcomes.
Ultimately, agent loops represent the operational foundation of autonomous AI. They transform language models from tools that respond to prompts into systems that can pursue objectives, adapt to changing conditions, and operate effectively within real-world software environments. As the industry moves toward increasingly agentic architectures, understanding and engineering these loops will become a important engineering skill for every team building the future of intelligent systems.
Stay tuned to the GoML blog for more on the latest in AI and ML.






