
Ledgebrook receives large volumes of submission and policy documents via email, each requiring classification as loss run or non-loss run. Manual processing was slowing down operations and increasing the chances of error. Partnering with GoML, Ledgebrook implemented gen AI underwriting agents on an AWS pipeline to scale and automate document classification in insurance workflows.
About Ledgebrook
Ledgebrook receives various submission and policy documents via email, which need to be classified as loss run or non-loss run, processed, and stored efficiently for underwriting and claims processing. goML automated the document processing workflow, eliminating manual efforts.
The problem: slow manual classification
Ledgebrook's underwriting team faced increasing challenges as document volumes surged. Each submission and policy document had to be manually reviewed and categorized, typically as either loss run or non-loss run, leading to time-consuming and repetitive workflows.
This manual process often introduced errors, delaying underwriting and impacting risk analysis.
With no system in place to track or group related documents, retrieval became a cumbersome task. As the company started handling greater volumes, the lack of automation in document handling became a major bottleneck, limiting operational agility and slowing decision-making across teams.
The solution: end-to-end document classification pipeline with AI for underwriting
GoML delivered a fully automated classification and retrieval system using AWS-native services and Gen AI models, built specifically for high-volume insurance document workflows.
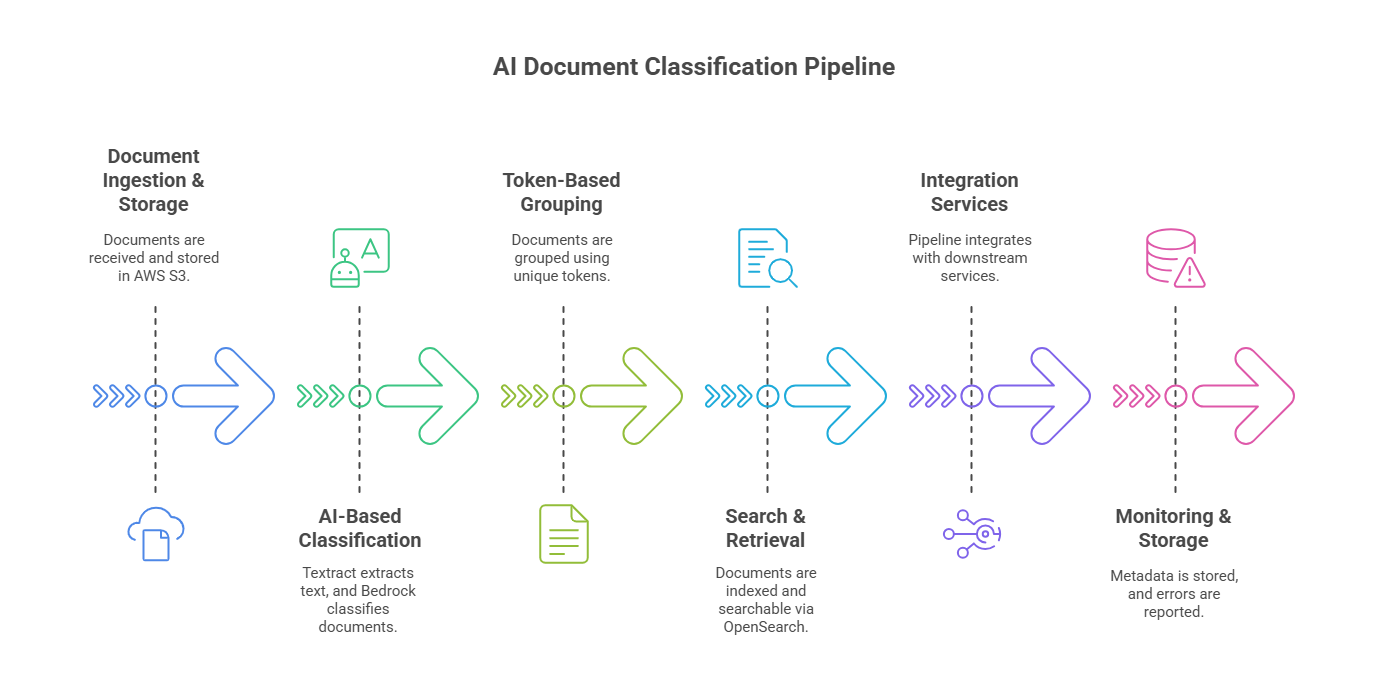
Document ingestion and storage
- Documents received via email were automatically routed and stored in an AWS S3 bucket.
- This allowed for centralized, scalable, and secure file storage while serving as the entry point to the Gen AI underwriting agent pipeline.
AI-based classification
- Using AWS Textract, raw text was extracted from each document. That content was processed through AWS Bedrock, leveraging AI for underwriting to accurately classify documents into "loss run" or "non-loss run" categories.
- This automation replaced a previously manual and error-prone step, significantly reducing human effort.
Token-based grouping
- Each group of related documents was assigned a unique aiDocumentSessionToken.
- This enabled structured grouping, traceability, and easy tracking across sessions, critical for managing large-scale insurance documentation pipelines. PostgreSQL RDS stored all session metadata.
Search and retrieval
- Processed documents were vectorized and indexed using OpenSearch Serverless.
- This allowed underwriters to retrieve files instantly using metadata and classification, a major leap in operational efficiency powered by gen AI for underwriting.
Integration services
- The pipeline integrated with other downstream systems.
- This enabled seamless handoffs to additional workflows, expanding the value of AI in underwriting automation.
Monitoring and storage
Metadata was securely stored in PostgreSQL RDS, with a webhook-based alert system for any processing errors or exceptions, ensuring full pipeline transparency.
The impact: improved efficiency and accuracy with AI underwriting agents
Ledgebrook realized measurable operational gains:
- 80% efficiency boost, eliminating manual review
- 90% improvement in classification accuracy, minimizing misfiled records
- 70% faster decision-making with real-time access to categorized documents
Lessons for insurance and insure-tech companies
Common pitfalls to avoid
- Relying on keyword search instead of structured metadata
- Treating classification as a one-time task instead of a pipeline
- Ignoring the value of grouping documents with tokens
Advice for teams facing similar challenges
- Automate early and focus on classification accuracy
- Integrate storage, metadata, and retrieval layers from the start
- Use AWS-native services for flexibility and scale
Want to reduce classification time by 80%?
Let GoML help you automate document classification with AI for underwriting just like Ledgebrook.
.png)
.png)


