
While frontier labs chase raw parameter scale, a quiet infrastructure war is being waged over a much more volatile metric for the computational economics of long context AI systems prefill phase. Basically, most AI teams today are no longer bottlenecked by model intelligence alone, but more so by context.
A model may be excellent at reasoning over a few pages of information, but real production workloads rarely look like that. Codebases span millions of tokens. Incident timelines stretch across logs, tickets, and docs. Enterprise workflows involve contracts, policies, transcripts, and historical decisions. The deeper the workflow, the more today’s systems depend on chunking, retrieval, summarization, and orchestration layers just to keep the problem manageable.
That is the backdrop for SubQ, a new model from Subquadratic that is being framed not as another incremental LLM release, but as an attempt to change the economics of long-context inference itself. The company’s core claim is bold: replace standard dense attention with a new mechanism called Subquadratic Sparse Attention (SSA), and suddenly million-token context stops being a luxury feature and starts becoming operationally usable.
If that claim holds, SubQ matters far beyond model benchmarking. It would affect how we build coding agents, memory systems, enterprise search, and AI infrastructure more broadly. If it does not hold, it still reveals something important, the AI industry is now actively searching for a way out of the quadratic attention bottleneck that has shaped the Transformer era.
Why long context AI is still broken
The dominant Transformer architecture scales poorly with sequence length because self-attention compares every token with every other token. In practical terms, this means that when context length doubles, the cost of attention grows roughly fourfold. Even with optimized kernels such as Flash Attention, the underlying scaling problem remains. The constants improve, but the shape of the curve does not.
That matters because the highest-value enterprise and developer workflows are increasingly long-context by default. A useful coding system may need repository-wide reasoning. A support copilot may need to work across months of threads and decisions. A legal assistant may need to read entire corpora instead of a handful of retrieved chunks. In all these cases, today’s systems often substitute architecture with pipeline complexity: retrieve some passages, summarize aggressively, route to tools, and hope the model sees enough of the truth to reason well.
This workaround has produced real products, but it has also created a ceiling. Retrieval can miss important evidence. Chunking can destroy structure. Summaries can flatten nuance. And long-context prompts often suffer from familiar failure modes such as lost-in-the-middle effects, attention dilution, and context rot. A model with a huge, advertised context window is not necessarily a model with huge functional context.
That distinction between nominal context and functional context is exactly where SubQ is trying to make its case.
What SubQ claims
SubQ is the flagship model from Subquadratic, a Miami-based AI startup founded by Justin Dangel and Alexander Whedon. Public coverage describes the company as an AI infrastructure startup focused on solving long-context scaling, with a reported $29 million seed round and positioning that is much closer to an architecture company than a typical application-layer AI startup.
The company says SubQ is built on a proprietary architecture called Subquadratic Sparse Attention, or SSA. The broad idea is simple to explain even if the implementation details are still mostly private: instead of computing attention across all token pairs, SSA tries to identify only the relationships that matter for the current input and compute attention over that sparse subset.
In theory, that changes the core scaling behavior of attention. Standard self-attention behaves quadratically. A sparse, content-dependent mechanism that only computes a limited number of interactions per token can push complexity much closer to linear behavior. That is the mathematical foundation behind SubQ’s pitch for scalable long context AI.
Subquadratic’s public materials make several headline claims:
- Up to 12 million tokens of context in the full system.
- A 1M-Preview model used in public benchmark discussions.
- Around 150 tokens per second at 12M context.
- Around 52x faster prefill than FlashAttention at 1M tokens.
- Nearly 1,000x less attention compute than standard dense attention at 12M tokens.
- A product suite that includes a full-context API, SubQ Code for coding agents, and SubQ Search for deep long-context search and research workflows.
Those are extraordinary claims. Some are clearly product claims. Some are architectural claims. And some sit in the gray zone between performance marketing and technical promise. That is why SubQ is getting both excitement and skepticism.

High-level architecture: What SSA claims to change
Standard self-attention for a sequence of length n computes:
Attention(Q,K,V)=softmax(QK⊤dk−−√)V
where
Q,K,V∈Rn×dk.
The matrix QK⊤ is n×n, so both compute and memory for attention scale as O(n2) in sequence length.
Even with Flash Attention-style kernel optimizations, you are still computing essentially all n2 interactions; the optimization is about how you do the same work, not how much work you do.
SSA’s core idea
Do not score every token against every other token.
Learn a sparse, content-dependent attention pattern that selects only the “important” key positions for each query.
Do exact attention on that subset, skipping the rest of the n2n2 matrix. If each query attends to only k keys on average, with k≪n, then the total number of attention score computations becomes O(nk) rather than O(n2). For roughly constant or slowly growing k, this behaves close to linear in n, which is what SubQ means by “sub-quadratic” attention.
Subquadratic describes SSA as “finding and focusing only on those relationships [between words] that matter, ensuring compute is used where it matters most,” and claims that at 12M tokens this yields almost 1000x less attention compute than standard dense attention, which is what SubQ means by “sub-quadratic” attention.

The intuition behind SSA
The easiest way to understand SSA is to start with the problem dense attention creates.
In a normal Transformer, every token gets a chance to compare itself with every other token. That is powerful, but it is also expensive. For a sequence of length n, attention requires building interactions across an n×n matrix. This is why long prompts become expensive so quickly in long context AI models.
SSA’s claim is that most of those interactions are not useful. If the model can learn which token-to-token relationships matter for a task, it can avoid paying the full cost of all-pairs attention.
So rather than asking every token to look at everything, SSA appears to use a content-dependent sparse selection strategy. In other words, the model decides where to look based on semantic relevance rather than fixed positional rules like sliding windows or block sparsity. That matters because many older sparse-attention approaches failed when the important dependency was far away and not captured by a predesigned pattern.
A clean mental model is this: dense attention is like putting every person in a company-wide meeting room and asking everyone to listen to everyone else. SSA is like routing each person to the few conversations that are relevant to the decision being made.
If that routing is accurate enough, the model can save enormous amounts of computation while preserving the information flow that matters. If it is not accurate enough, you get efficiency at the cost of capability. That tradeoff is the entire SubQ debate.

Why this matters for coding agents first
SubQ is being marketed heavily around software engineering, and that is not accidental.
Coding is one of the cleanest high-value examples of a long context AI problem. Useful coding systems do not just need to autocomplete a function. They need to understand architecture across files, dependencies across modules, design intent across pull requests, and historical decisions across issue threads. In large repositories, the relevant context for one bug or refactor can be spread across an enormous working set.
Most current coding assistants solve this with a mixture of indexing, retrieval, selective file inclusion, and orchestration. That works surprisingly well, but it also means the assistant is operating through a carefully engineered bottleneck. It is rarely seeing the full system directly.
This is where SubQ Code becomes interesting. The company describes it as a long-context layer for existing coding agents and IDE copilots. Rather than replacing tools like Claude Code, Cursor, or Codex-style systems outright, it appears to offer a routing-based architecture where especially expensive long-context steps are pushed onto SubQ.
That is smart product strategy. It lowers adoption friction and targets exactly the part of the workflow where standard context windows hurt the most. If the model can truly handle repository-scale reasoning economically, it could improve codebase mapping, deep refactors, dependency tracing, multi-PR analysis, and long-running autonomous software workflows.
But even here, caution is important. Full-repository access does not automatically equal better software engineering. Coding still depends on planning, validation, tool execution, and iterative refinement. Context is a major lever, not a complete solution.
What the benchmarks suggests?
The benchmark results suggest that SubQ is not just claiming efficiency gains in theory it is also showing strong performance on tasks that directly reflect its architectural strengths. On MRCR v2, which tests long-context retrieval at 1M tokens, SubQ scores 62.0%, clearly ahead of Gemini 3.1 Pro, GPT-5.4, and Claude Opus 4.7 in the chart. That points to a model that can preserve and recover information well across very large contexts, which is exactly where sparse attention should matter most for long context AI.
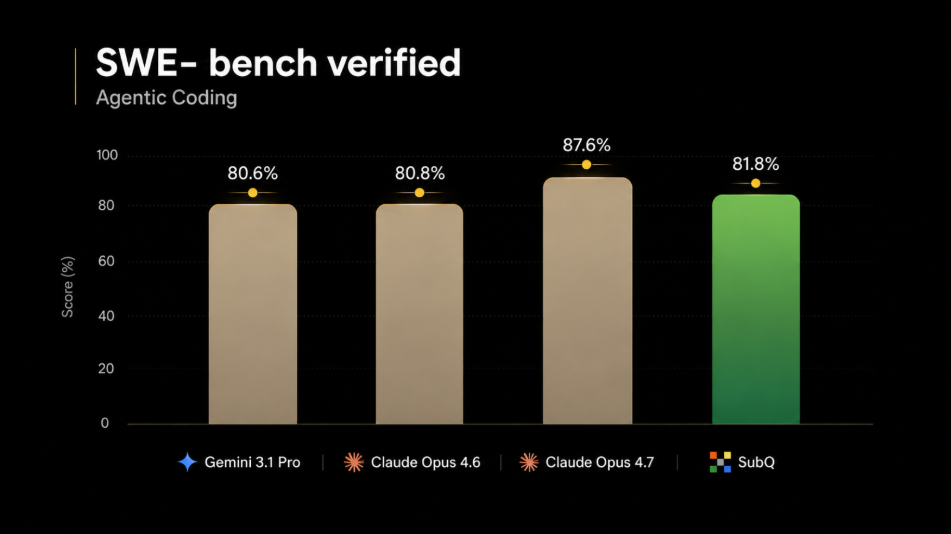
On SWE-Bench Verified, SubQ reaches 81.8%, placing it close to the best frontier models and ahead of Gemini 3.1 Pro, though still slightly below Claude Opus 4.7. That suggests SubQ is not only strong at long-context retrieval, but also competitive on real agentic coding tasks where reasoning, code understanding, and patch generation all matter.
Taken together, the charts suggest a clear pattern. SubQ’s architecture appears especially effective in long-context settings, and its performance remains competitive even when the task shifts to coding. In other words, the model seems to be doing what its design promises turning long context from a cost burden into a practical advantage.

What does that pattern tell us?
It suggests that SubQ’s strongest case today is long-context retrieval and long-range information access, not necessarily outright dominance across every coding benchmark. That makes sense. If SSA is real and effective, it should show up first in tasks where the model’s ability to find and use buried information matters most.
The company also emphasizes systems-level improvements, especially during prompt ingestion or prefill, where long-context cost becomes painful. The public figures around 52x faster prefill at 1M context and large attention-FLOP reductions are particularly notable because they speak to deployment economics, not just leaderboard optics.
Still, benchmark interpretation here needs discipline. These are partly self-reported results. The benchmark set is still selective. And the strongest claims around 12M context are not yet backed by broad public evaluation at that exact scale.
The reason people are skeptical
SubQ has landed in exactly the kind of territory where AI engineering gets most interesting: a technically plausible story paired with unusually strong marketing claims.
On the positive side, the problem is real, the intuition is strong, the benchmark choices are directionally sensible, and the product positioning is coherent. AI teams genuinely need better ways to scale context without drowning in retrieval and orchestration complexity.
On the skeptical side, several important things are still missing.
There is no peer-reviewed paper, no open-weight release, no public implementation of SSA, and limited independent benchmarking. The most important details about routing, training, hardware mapping, and failure cases are still not public. It is also not yet clear how well the model maintains quality as it approaches the top end of its advertised 12M-token range.
This is not a trivial concern. The history of long-context AI is filled with systems that advertised huge windows but failed to convert that into useful reasoning. Models can ingest massive context and still struggle to retrieve the right facts, preserve relevance, or reason consistently across very long spans.
So, the right posture toward SubQ today is not dismissal, but disciplined curiosity.
Could this change AI infrastructure?
If SubQ works anywhere close to how it is being pitched, the implications are significant.
- First, it changes the economics of context engineering. Many current AI systems are complex largely because context is scarce and expensive. If functional long-context becomes dramatically cheaper, parts of the current retrieval-heavy stack become optional rather than mandatory.
- Second, it changes how we think about agents. A great deal of current agent orchestration exists to work around memory and context limits. Multi-step decomposition, recursive summarization, and tool chaining are often not just intelligence strategies; they are compensation strategies. If a model can hold far more relevant state inside one working context, the design space for agents shifts.
- Third, it could materially affect coding infrastructure. IDE copilots, code review bots, repo navigation systems, and autonomous engineering agents all become more powerful if they can reason over much larger working sets directly.
- Fourth, it puts pressure on the broader ecosystem: model providers, retrieval startups, vector databases, and inference infrastructure vendors. If long context AI becomes cheaper, some layers in today’s AI stack become less essential, while others become more strategic.
That said, it is unlikely that SubQ or any similar model completely replaces retrieval, vector databases, or orchestration. Those systems solve more than one problem. They help with freshness, scale, structure, access control, and cost. The likely future is not “RAG dies,” but “the boundary between retrieval and direct context shifts.”

The bigger story behind SubQ
The most important thing about SubQ may not be whether every launch claim holds perfectly. It may be that the industry is now openly searching for a new scaling path.
For years, the default pattern in frontier AI has been clear: train larger models, improve data, optimize kernels, and add more infrastructure around dense Transformers. That path still works. But it is also increasingly expensive, and long-context use cases are exposing one of its deepest structural limitations.
SubQ is one of the clearest recent signals that the next wave of progress may come not just from better models, but from better compute allocation inside models.
That is why the company’s slogan, “Efficiency is Intelligence,” is more than branding. It is a thesis about where future AI capability comes from. If a model can spend its budget on the right interactions instead of all interactions, it may unlock a different class of systems altogether.
Final take
SubQ deserves attention because it is attacking a real bottleneck with an architecture-level claim rather than a surface-level feature. The problem it is targeting quadratic attention in long-context workloads is one of the clearest limits in today’s AI stack. The public benchmark picture is promising enough to take seriously, especially for long-context retrieval and coding-adjacent tasks.
At the same time, the strongest parts of the story remain unverified. Until there is deeper technical disclosure, independent benchmarking, and broader public testing, SubQ should be treated as an important development to watch rather than a settled breakthrough.
But even in that cautious framing, it matters.
Because if long-context AI is the next real bottleneck, then architectures like SSA are not a side story. They are the story.
References
- Subquadratic homepage: https://subq.ai
- Introducing SubQ: https://subq.ai/introducing-subq
- How SSA Makes Long Context Practical: https://subq.ai/how-ssa-makes-long-context-practical
- Explainx analysis: https://explainx.ai/blog/subq-ssa-sparse-attention-12m-context-2026
- The SaaS News funding summary: https://www.thesaasnews.com/news/subquadratic-raises-29m-seed-funding
.jpg)




