

Introduction:
A ground-breaking invention created by Meta is called Code Llama. It is an advanced large language model (LLM) created to transform the coding process. Code Llama is uniquely trained on a large dataset that includes both code and natural language, allowing it to generate code, provide code-related explanations in plain language, and help programmers in whole new ways.Code Llama's Operation:The strength of Code Llama comes from its huge training data, which consists of descriptions of code written in a wide range of programming languages. Code Llama learns the subtle relationships between code and the human language used to describe it by digesting this varied dataset.After being educated, Code Llama can be used as a variety of tools by developers. You can tell it to write code based on descriptions of problems in plain language. As an alternative, you can give Code Llama already written code and ask it to be improved, finished, or debugged. Your imagination is the sole constraint on its uses.Infilling:Code Llama masters infilling, filling coding gaps based on context, ideal for docstring generation and real-time code completion. It uses causal masking, shuffling sequences for prediction, and splits documents into prefix, middle, and suffix segments for training.Long input contexts:Code Llama enables extended input context, crucial for repository-level reasoning and synthesis tasks. Handling long sequences is a challenge for transformer models, but Code Llama introduces Long Context Fine-Tuning (LCFT). LCFT allows training on 16,384-token sequences without substantial cost increase, akin to position interpolation-based fine-tuning. By modifying position embeddings, it enhances the ability to manage much longer sequences effectively.Instruction fine-tuning: Code Llama's safety and utility are boosted through instruction fine-tuning. Models in Code Llama - Instruct are optimized to respond to queries, using the "RLHF V5" dataset created via reinforcement learning and human input. This dataset inherits safety and instruction-following features from Llama 2, enhancing Code Llama's ability to provide safe and accurate responses.

The Code Llama specialization pipeline. The different stages of fine-tuning annotated with the number of tokens seen during training. Infilling-capable models are marked with the ⇄ symbol.Code Llama variants:Code Llama is available in three variants:
- Code Llama: a foundational model for code generation tasks
- Code Llama - Python: a version specialized for Python.
- Code Llama - Instruct: a version fine-tuned with human instructions and self-instruct code synthesisdata.
Benefits of using Code Llama:Code Llama has a lot of benefits, including:Enhanced Productivity: By utilizing Code Llama's features, developers may create code more quickly and effectively, cutting down on development time.Improved Code Quality: By producing well-structured and well-documented code snippets, Code Llama aids in maintaining code quality.Reduced problems: The methodology helps programmers find and fix problems in their code, increasing the reliability of their product.Lower Entry Barrier: Code Llama can make coding more approachable, allowing users to learn and create even with little to no prior coding knowledge.Dataset:Training dataset of Code Llama and Code Llama – Python. We train Code Llama on 500B additional tokens and Code Llama - Python further on 100B tokens.

How Code Llama worksAn improved version of Llama 2 that is focused on coding tasks is called Code Llama. It excels at creating and explaining code in response to code or natural language cues since it was extensively trained on datasets that were specialized in writing code.Coding from scratch, code completion, and debugging support are some examples of these jobs. It is an effective tool for developers and programmers because it works with popular programming languages like Python, C++, Java, PHP, TypeScript (JavaScript), C#, and Bash.Presenting three Code Llama variants: 7B, 13B, and 34B, each trained on a whopping 500B tokens of code and code-related data.The fill-in-the-middle (FIM) functionality of the 7B and 13B models allows them to insert code into already existing code, which makes them ideal for jobs like code completion.Different demands are met by these models. The 34B model provides excellent coding aid, whereas the 7B model is effective and can run on a single GPU.Faster and more suited for low-latency activities like real-time code completion are the smaller models (7B and 13B).


All Code Llama models excel on inputs with sequences of up to 100,000 tokens and deliver consistent outputs with context up to 100,000 tokens.Longer context opens up new opportunities, such as giving relevant code generations more context and assisting with massive codebase debugging. When debugging large code portions, developers can make efficient use of the model.Code Llama pass@ scores on HumanEval, MBPP and Multilingual Human Eval.
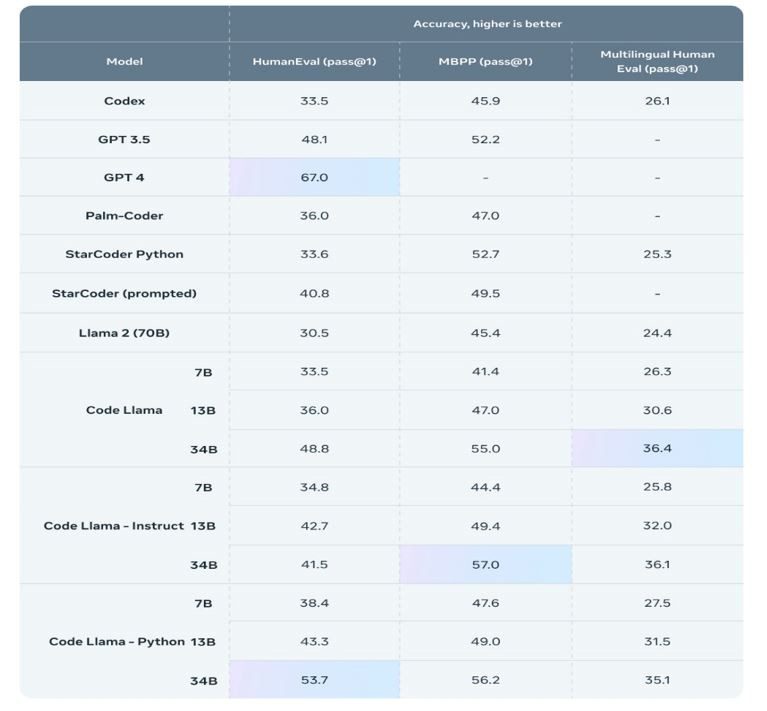
The pass@1 scores of our models are computed with greedy decoding. Models are evaluated in zero-shot on Human Eval and 3-shot on MBPP. The instruct models are trained to be safe and aligned from the base Code Llama models.Conclusion:Code Llama is a game-changing advancement in code-related language models. With various model sizes, infilling capabilities, and fine-tuning techniques, it offers powerful tools for a wide range of coding tasks, from generation to debugging. Code Llama excels at handling longer inputs, prioritizes safety, and supports multiple programming languages, making it an invaluable asset in modern software development. In the era of AI-assisted coding, Code Llama emerges as a promising companion, streamlining coding processes and boosting productivity in the ever-evolving software development landscape.





